🧭 목차
| 구분 | 증명 핵심 |
|---|---|
| A. GitOps 분리 | Triton dev/prod 독립 배포 및 상태 고정 |
| B. 모델 제어 | NFS model-repo 분리 + explicit load 통제 |
| C. 서빙 검증 | load → ready → infer E2E 성공 |
| D. 관측 가능성 | /metrics → Prometheus → Grafana 연계 |
| E. 배포 통제 | MLflow→Airflow 검증 체인 + commit/rollback |
| F. 알럿 분리 | Alertmanager null default 기반 dev/prod 분리 |
| G. 알럿 실증 | Triton latency 알럿 E2E 동작 |
A. Triton GitOps & Dev/Prod 분리
1️⃣ ArgoCD Applications (GitOps 기준)
✔ dev/prod 애플리케이션 상태 증명
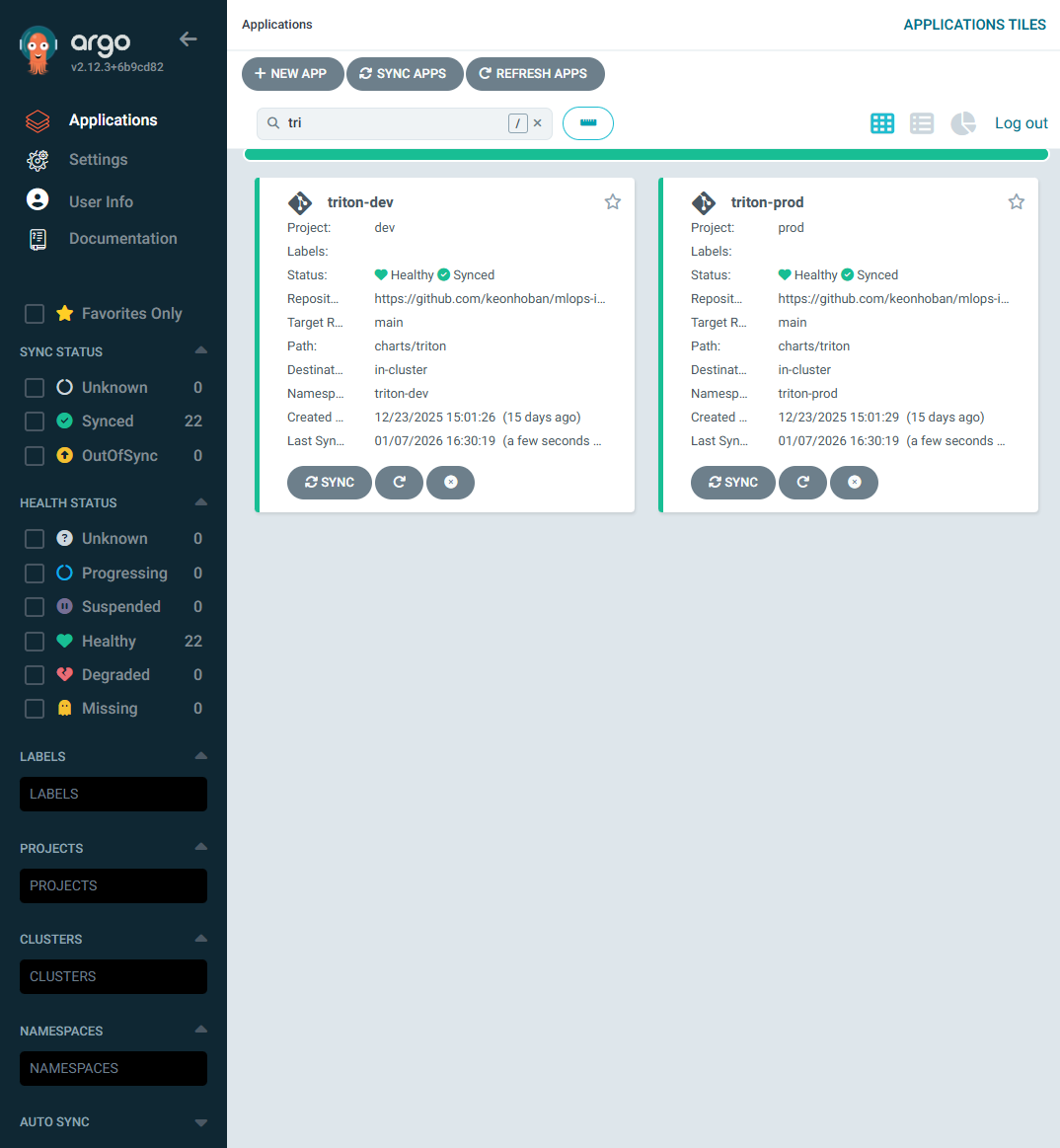
📸 proof-triton-01.png
- ArgoCD UI에서
triton-dev,triton-prod애플리케이션 목록 - Status: Synced / Healthy
(캡처: ArgoCD Applications 화면 – triton-dev / triton-prod)
확인 포인트
- dev/prod Triton이 서로 다른 Application으로 존재
- Git 변경 없이도 idempotent 상태 유지
👉 결론
Triton은 GitOps 기준으로 dev/prod가 독립 배포되며, 운영 중 수동 개입 없이 안정적으로 유지됩니다.
B. Model Repository & Explicit Control
1️⃣ NFS model-repo 구조 증명
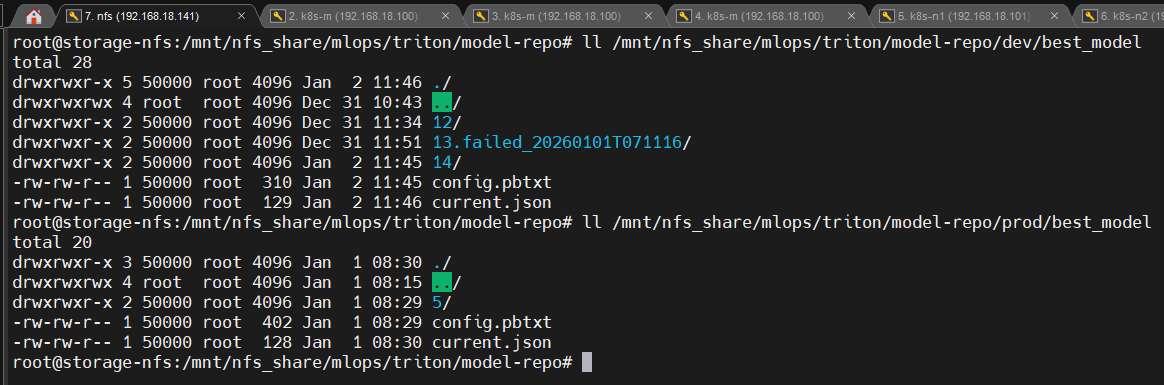
📸 proof-triton-02-01.png
- NFS 디렉터리 트리
/model-repo/dev/best_model/.../model-repo/prod/best_model/...
(캡처: dev/prod model-repo 디렉터리 구조)
확인 포인트
- dev/prod가 물리적으로 다른 경로 사용
- 동일한 PVC 이름이라도 namespace 격리로 충돌 없음
👉 결론
모델 저장소가 환경별로 분리되어 교차 오염 위험이 구조적으로 차단됩니다.
실패한 모델 버전은 삭제하지 않고 .failed_* 디렉터리로 격리하여
재현 및 사후 분석이 가능하도록 설계했습니다.
2️⃣ explicit 모델 제어 증명
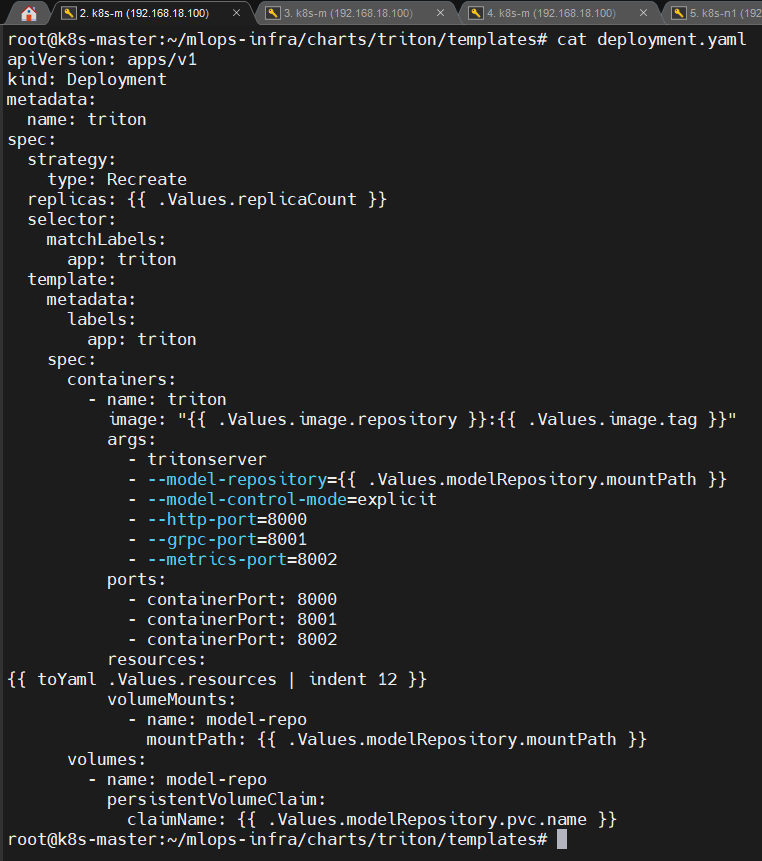
📸 proof-triton-02-02.png
- Triton Deployment args
model-control-mode=explicit
(캡처: Triton Deployment spec / args)
확인 포인트
- 자동 로딩 비활성화
- 명시적 load 호출 시에만 모델 활성
👉 결론
모델 교체는 항상 사람이 인지 가능한 통제된 위험 구간으로 관리됩니다.
C. Serving E2E 검증 (Load → Ready → Infer)
1️⃣ 모델 로드 & 상태 검증
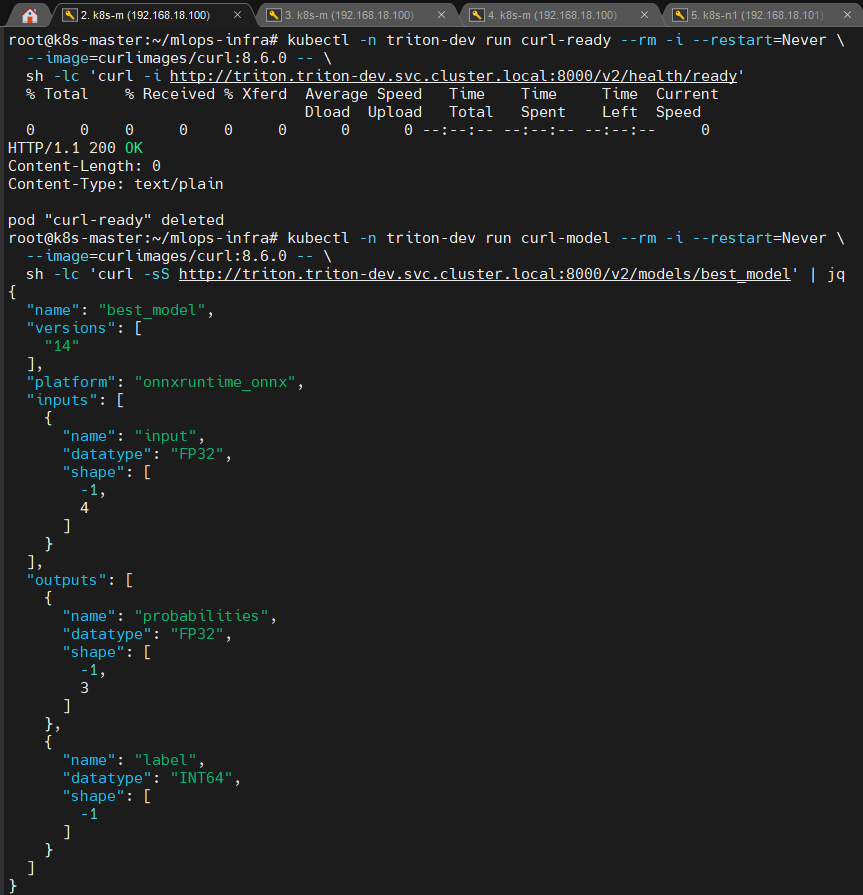
📸 proof-triton-03-01.png
/v2/health/ready→ 200 OK/v2/models/{model}→ input/output schema 노출
(캡처: curl 결과 또는 Postman / HTTP client 응답)
👉 결론
모델이 Triton 내부에 정상 로딩되어 실행 가능한 상태임이 확인됩니다.
2️⃣ 추론(infer) 성공 증명
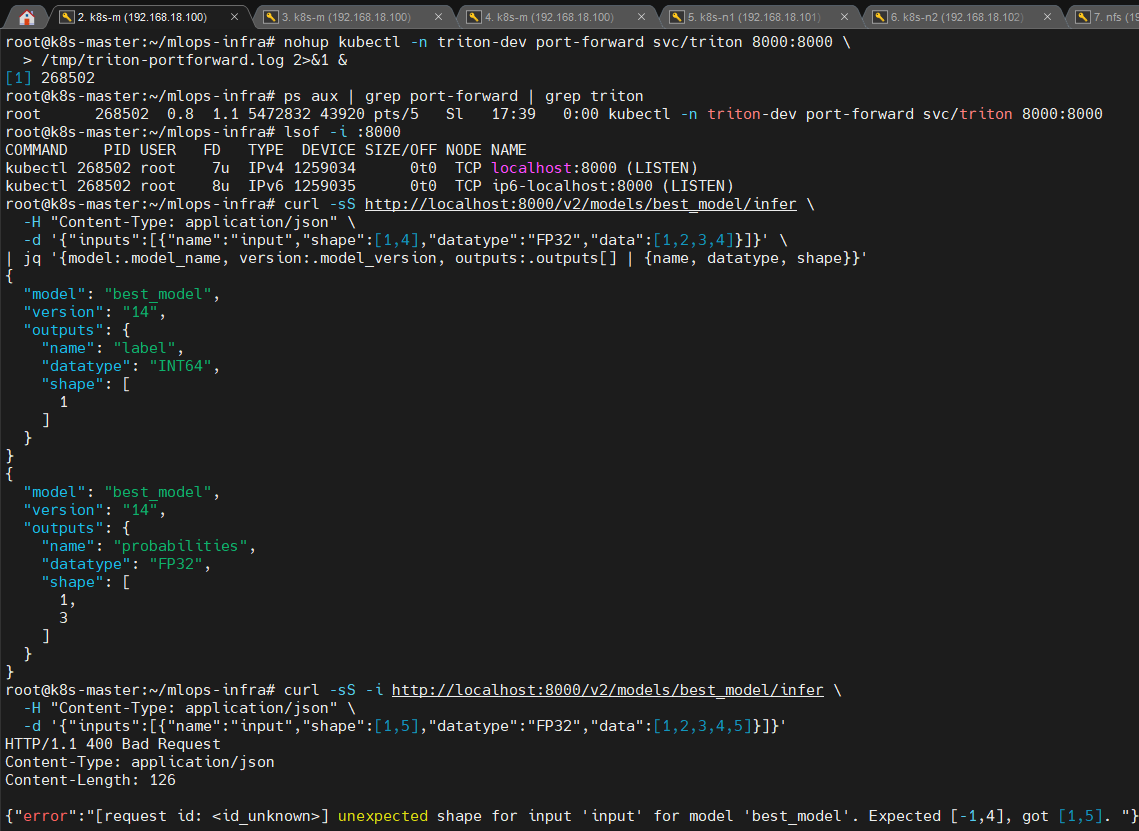
📸 proof-triton-03-02.png
- 정상 입력 시 inference response 반환
- 잘못된 shape/config 시 load 또는 infer 단계에서 실패
(캡처: 정상 infer 응답 / 실패 케이스 로그)
👉 결론
Triton의 schema 검증이 load/infer 단계에서 모두 동작함을 실험으로 확인했습니다.
D. Observability 증명
1️⃣ Triton /metrics 노출 증명
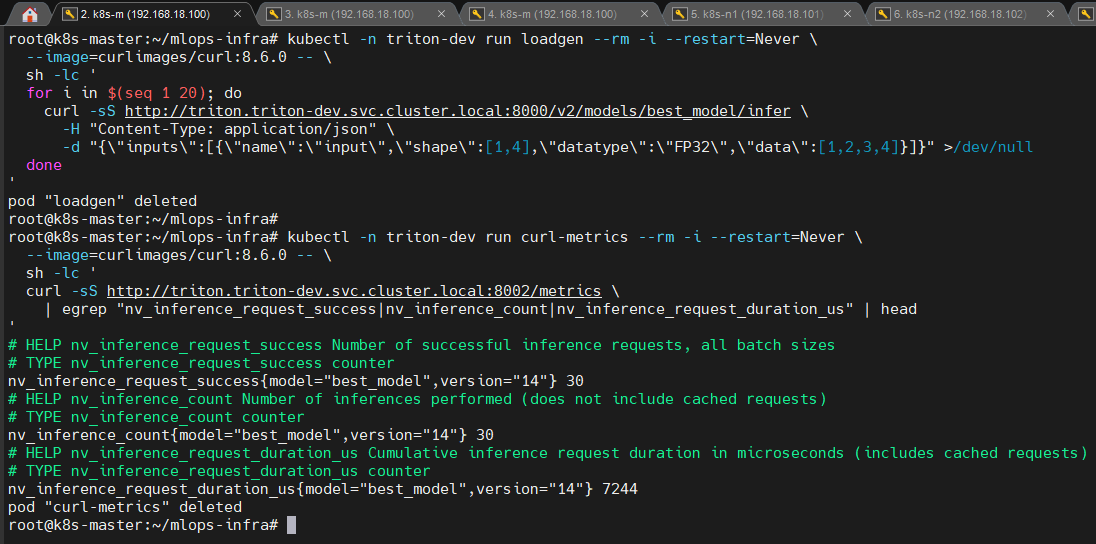
📸 proof-triton-04-01.png
/metrics엔드포인트nv_inference_*계열 메트릭 등장
(캡처: metrics 출력 일부)
👉 결론
Triton은 실제 추론 실행을 메트릭으로 증명 가능한 서빙 컴포넌트입니다.
2️⃣ Prometheus scrape 분리 증명
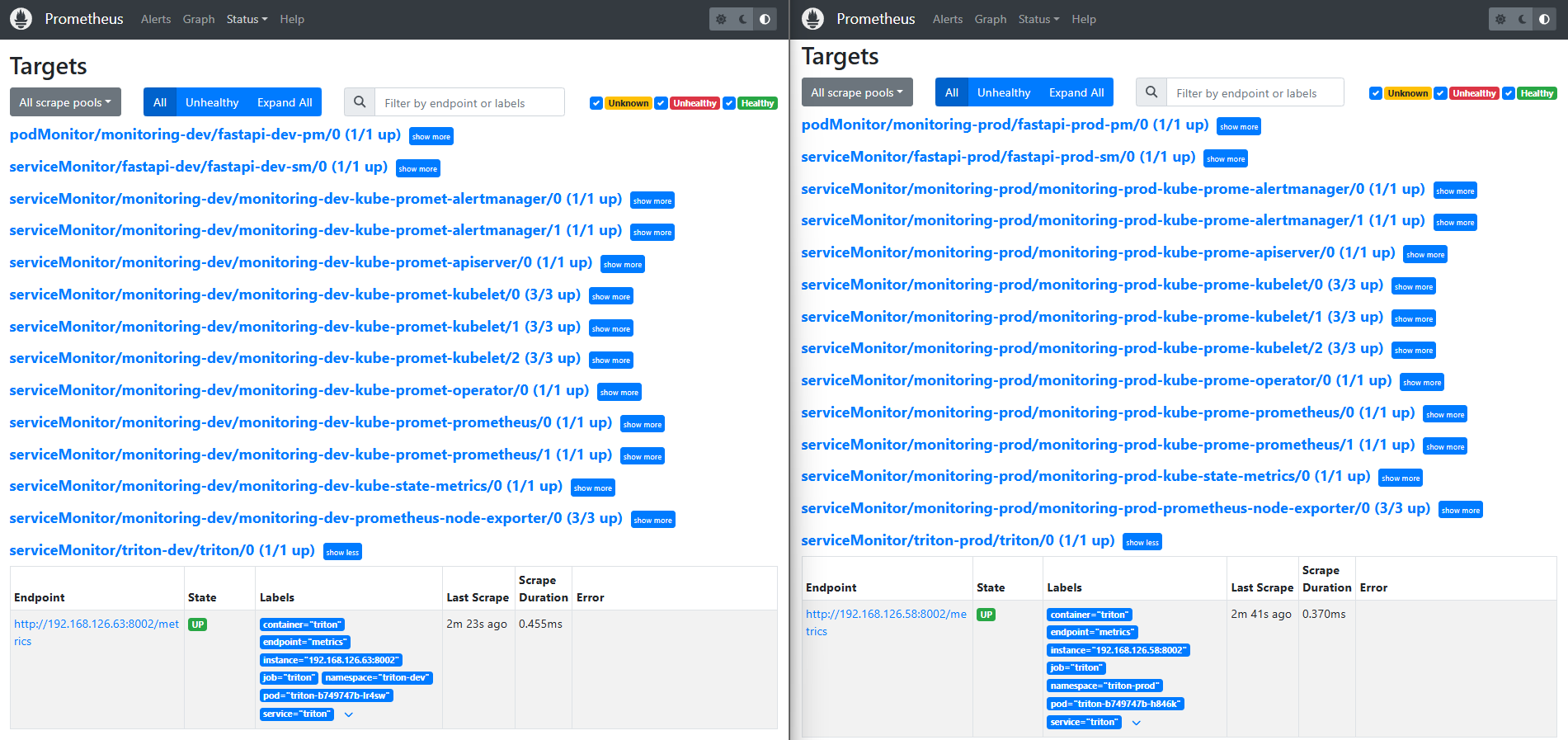
📸 proof-triton-04-02.png
- Prometheus Targets 화면
- triton-dev → monitoring-dev
- triton-prod → monitoring-prod
👉 결론
dev/prod Prometheus가 서로 다른 namespace만 수집하도록 강제됩니다.
3️⃣ Grafana 대시보드 증명
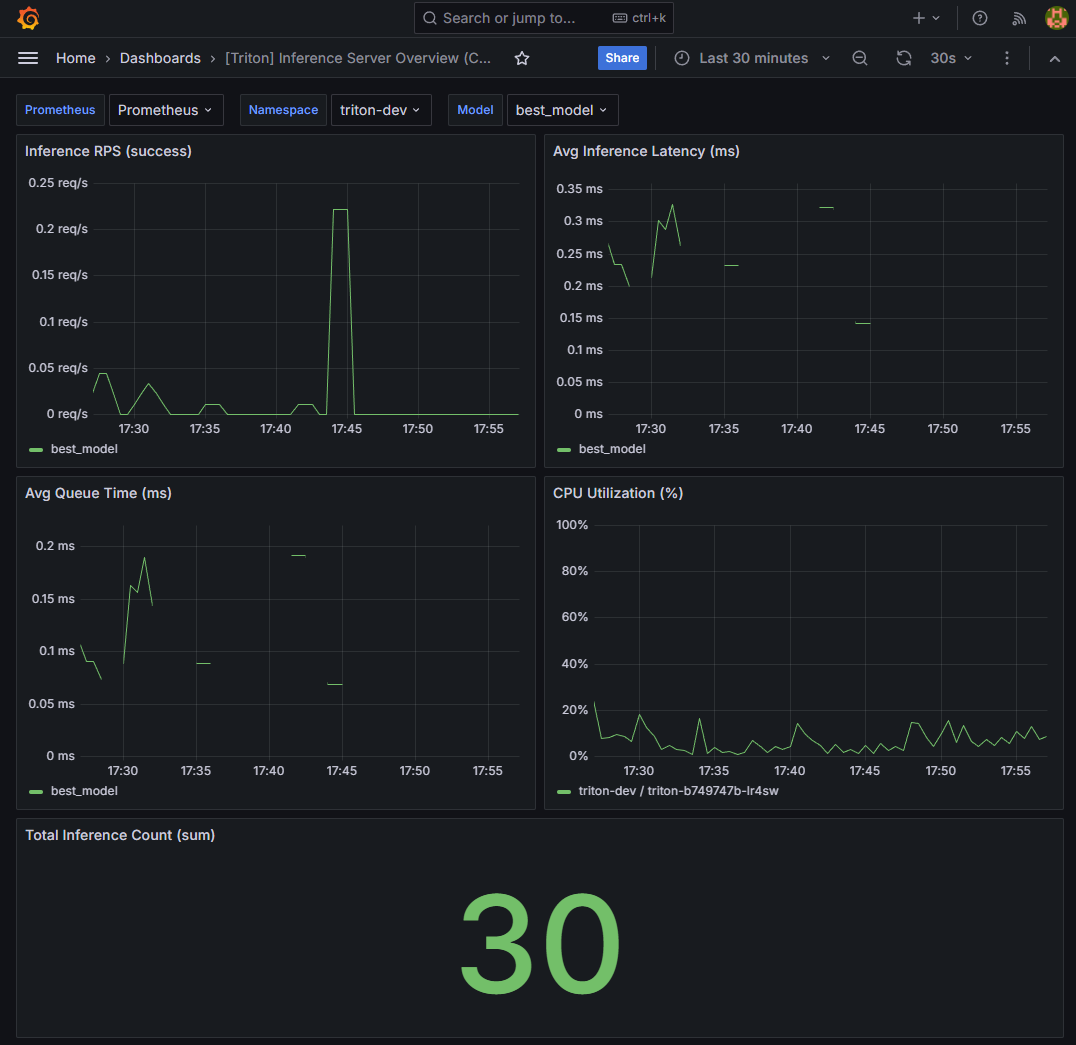
📸 proof-triton-04-03.png
- RPS
- Mean Latency
- Queue Time
- CPU / Request Count
👉 결론
Triton 서빙 상태가 대시보드로 즉시 판단 가능한 운영 단위로 관측됩니다.
E. MLflow → Airflow → Triton 배포 파이프라인 증명
1️⃣ DAG 검증 체인 증명
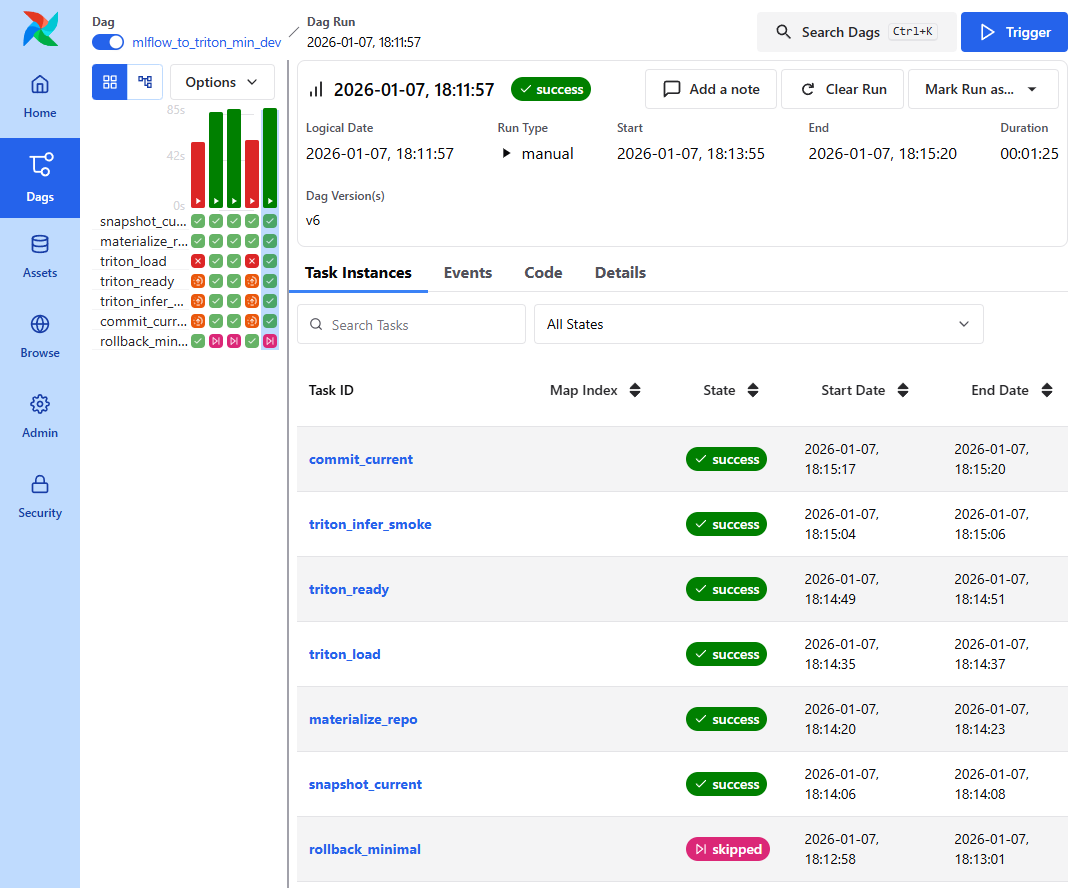
📸 proof-triton-05-01-01.png
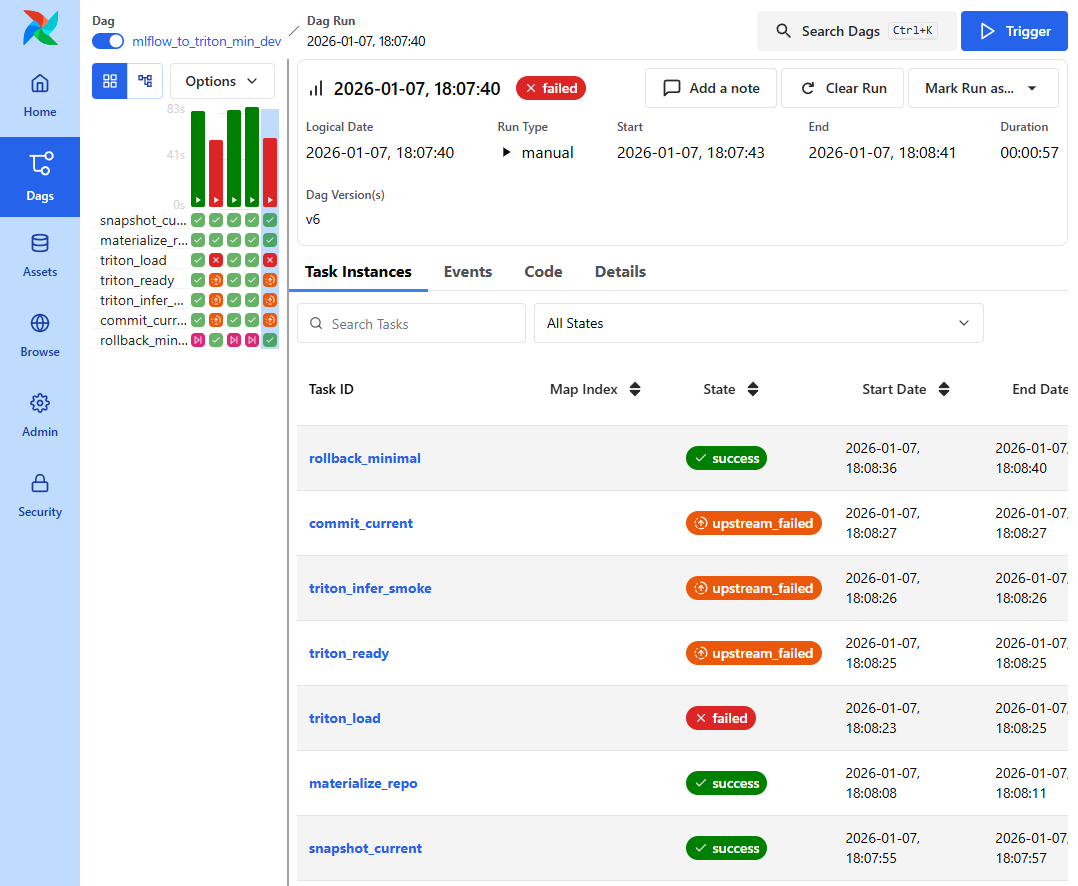
📸 proof-triton-05-01-02.png
- Airflow DAG Graph View
- 모든 task 성공 시
commit_current - 실패 시
rollback_minimal실행
👉 결론
배포는 검증 체인 기반 상태 전이로 고정됩니다.
성공과 실패 케이스를 모두 재현함으로써, 본 파이프라인이 이론이 아닌 실제 운영 기준으로 동작함을 증명했습니다.
배포 성공의 기준은 ‘로드’가 아니라 ‘검증 체인 통과 후 commit’입니다.
2️⃣ current.json 운영 상태 증명
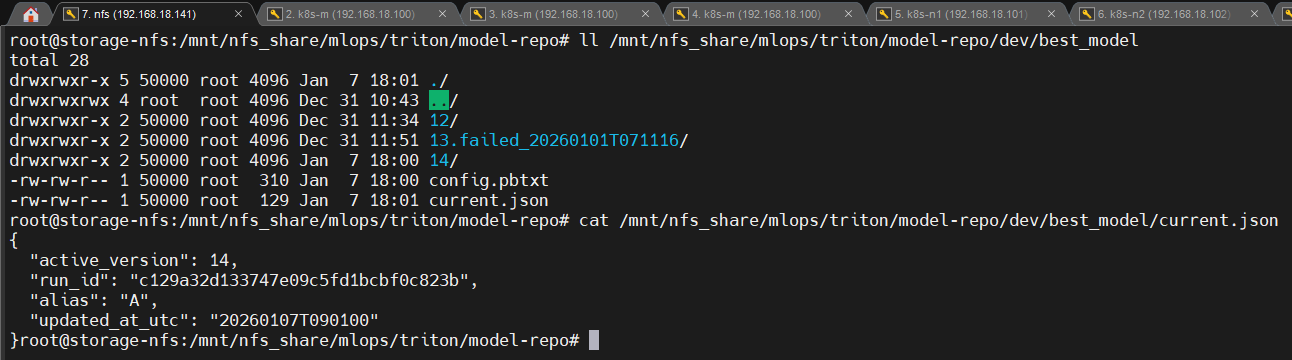
📸 proof-triton-05-02-01.png
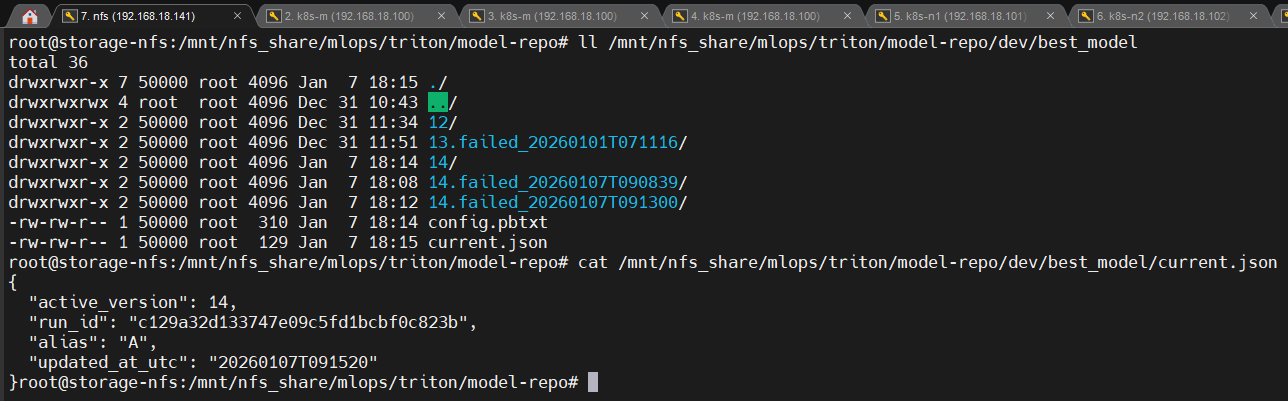
📸 proof-triton-05-02-02.png
- current.json 내용 변경 전/후
👉 결론
운영 상태가 사람이 아닌 시스템이 해석 가능한 단일 기준으로 관리됩니다.
F. Alerting 운영 표준 (Dev/Prod 분리)
1️⃣ Alertmanager null default 증명
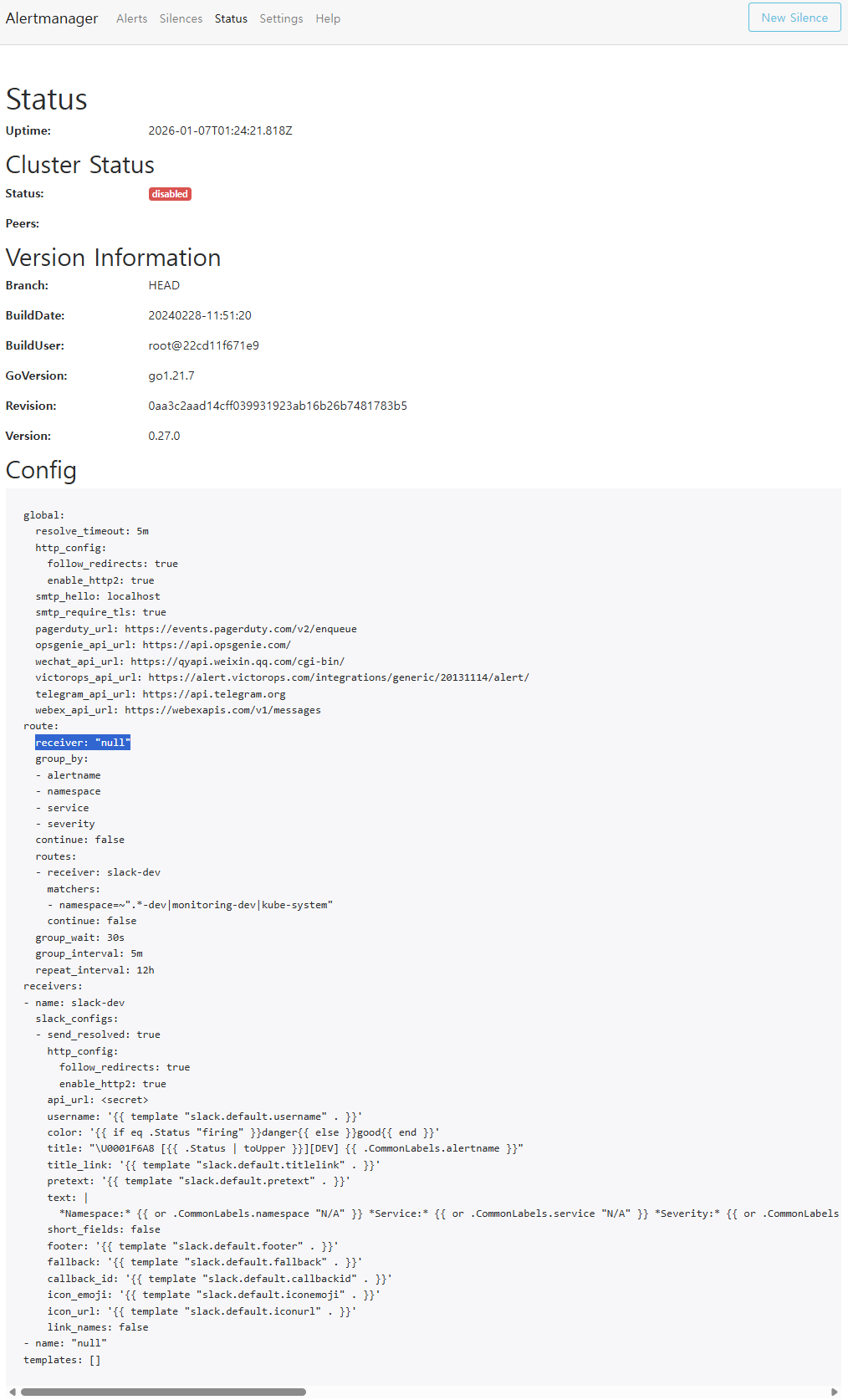
📸 proof-triton-06-01.png
- Alertmanager route 설정
- default receiver = null
👉 결론
라벨 실수나 설정 오류가 있어도 운영 채널 오염이 발생하지 않습니다.
알럿은 ‘보내는 것’보다 ‘보내지 말아야 할 것을 막는 것’이 더 중요합니다.
G. Triton Serving Alerts 검증 (E2E)
1️⃣ 알럿 정의 적용 증명
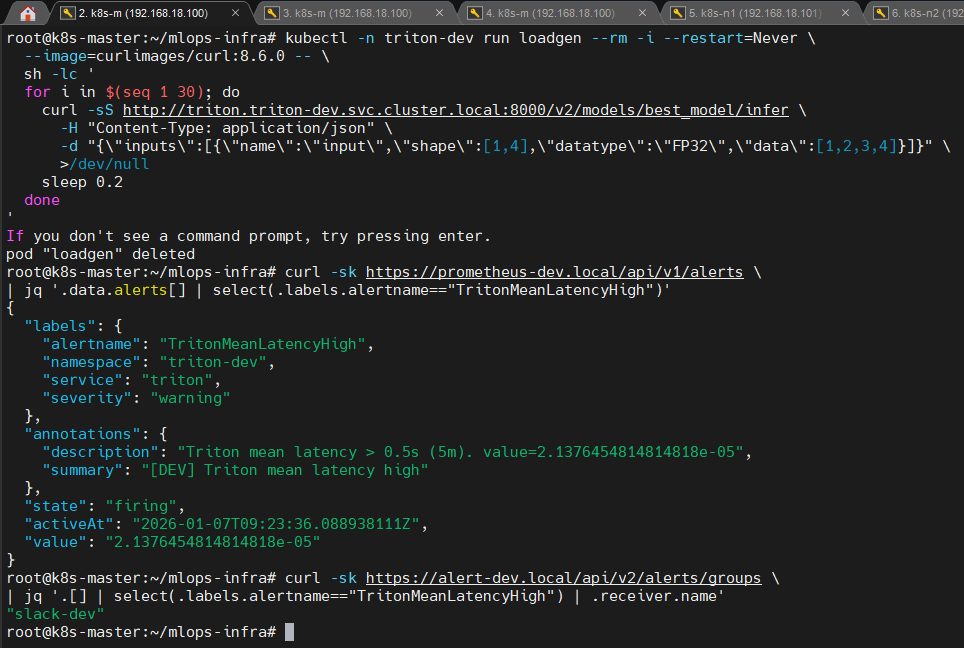
📸 proof-triton-07-01.png
TritonMeanLatencyHighPrometheusRule
2️⃣ 알럿 firing → Slack 수신 증명
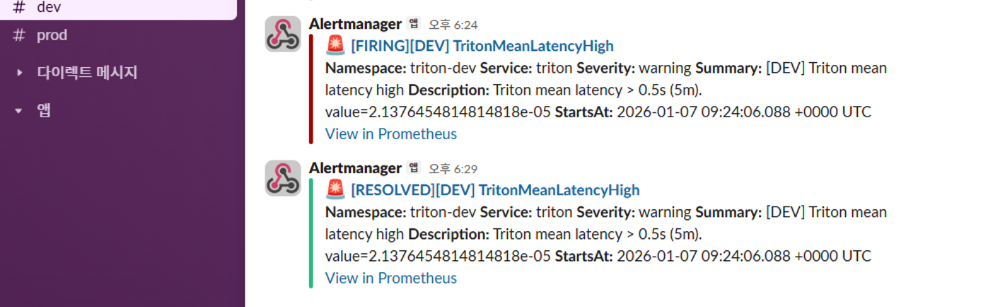
📸 proof-triton-07-02.png
- Grafana / Prometheus에서 alert firing
- Alertmanager receiver 선택
- Slack(dev/prod) 메시지 수신
👉 결론
Triton 서빙 품질 알럿이 정확한 환경으로만 전달됩니다.
3️⃣ HighErrorRate 알럿 설계 근거
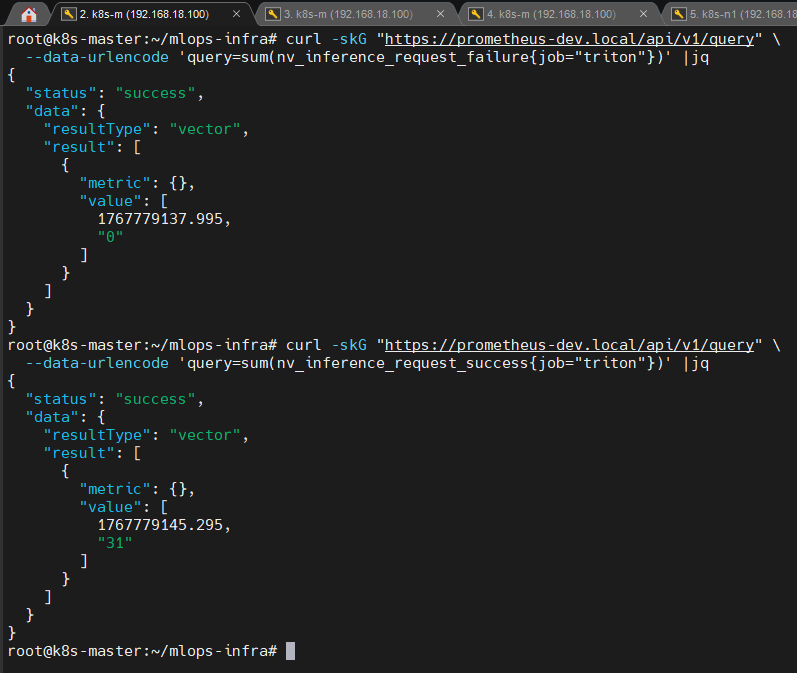
📸 proof-triton-07-03.png
nv_inference_request_success > 0nv_inference_request_failure = 0- (잘못된 요청·HTTP 실패를 반복 발생시킨 이후의 Prometheus query 결과)
👉 결론
nv_inference_request_failure는 HTTP 요청 실패가 아니라
Triton 내부 모델 실행 단계 실패만을 카운트함이 실험으로 확인되었습니다.
따라서 TritonHighErrorRate는 테스트용 알럿이 아닌
운영 중 모델 실행 이상을 감지하는 알럿으로 유지하고,
HTTP 실패율은 Gateway 레이어 지표로 분리 관측하는 것이 정확합니다.
🏁 정리
- Triton은 GitOps로 dev/prod 분리 배포되고
- explicit 모델 제어 + NFS model-repo로 운영 통제가 가능하며
- load/ready/infer로 서빙 E2E가 증명되고
- 메트릭 기반 관측이 가능하며
- 배포는 검증 체인 + 최소 롤백으로 운영화되었고
- Alertmanager 정책으로 dev/prod 알럿 신뢰성이 보장됩니다.