🧭 목차
| 구분 | 증명 포인트 |
|---|---|
| A. Observability | 메트릭·로그·알람 dev/prod 완전 분리 |
| B. FastAPI & Platform Observability | FastAPI + Platform 대시보드 정상 동작 |
| C. Data Pipeline | Raw→Feature ETL 자동 실행 성공 |
| D. Data Pipeline Advanced | 버전·스키마·메타데이터·관측 등 운영형 구조 |
A. Observability 계층
Observability 계층(모니터링 + 로그 수집 + 알람)이
GitOps 기반으로 dev/prod 완전 분리 + 자동화 되어 있음을 증명합니다.
1️⃣ ArgoCD Applications (GitOps 기반 구성)
✔ 1-1. CLI로 전체 Application 상태 확인
kubectl -n argocd get applications
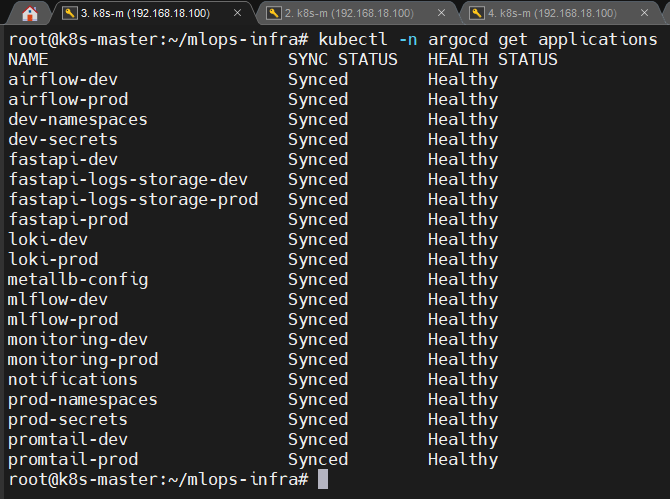
📸 proof-01-01-argocd-all-status-cmd.png
확인 포인트
airflow-dev/prodfastapi-dev/prodmlflow-dev/prodmonitoring-dev/prod(Prometheus + Grafana + Alertmanager)loki-dev/prod,promtail-dev/prodfastapi-logs-storage-dev/prodmetallb-configdev/prod-namespaces,dev/prod-secrets
→ SYNC STATUS = Synced, HEALTH STATUS = Healthy
👉 결론: GitOps 기준으로 모든 Observability 관련 앱이
항상 정합 상태(idempotent) 로 유지되고 있습니다.
✔ 1-2. ArgoCD UI — 전체 Applications
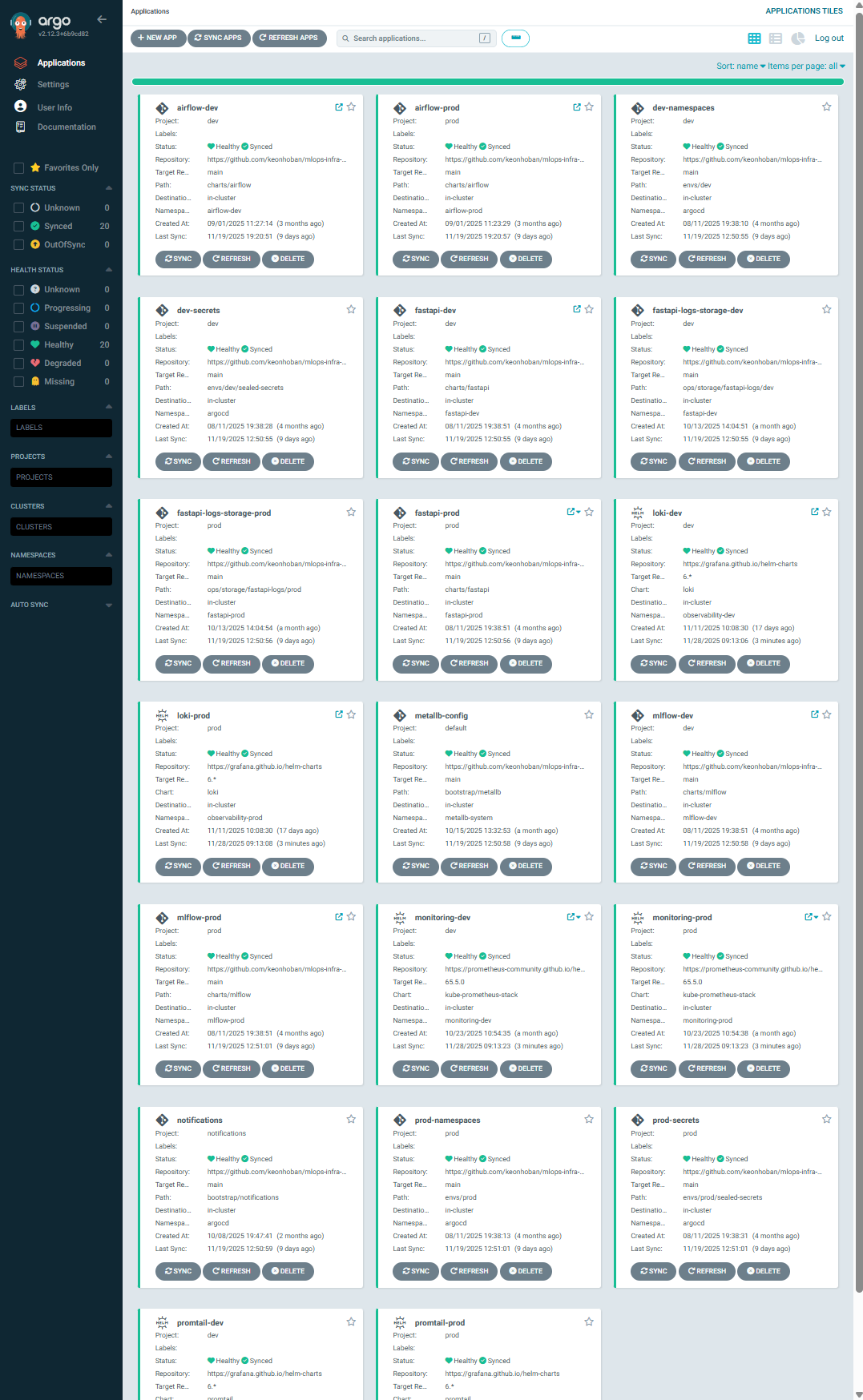
📸 proof-01-02-argocd-all-status.png
확인 포인트
각 Application의 Repository / Revision / Chart 버전이 명확히 표기
Destination namespace가 역할에 맞게 정확히 분리 (dev / prod)
CreatedAt, LastSynced 로 GitOps 동기화 상태 확인 가능
fastapi / logs-storage / loki / promtail / monitoring 이
서로 다른 네임스페이스로 배포됨
👉 결론: ArgoCD UI에서도 dev / prod 완전 분리 GitOps 구조가 명확하게 드러납니다.
✔ 1-3. ArgoCD UI — Observability 관련 앱만 필터링
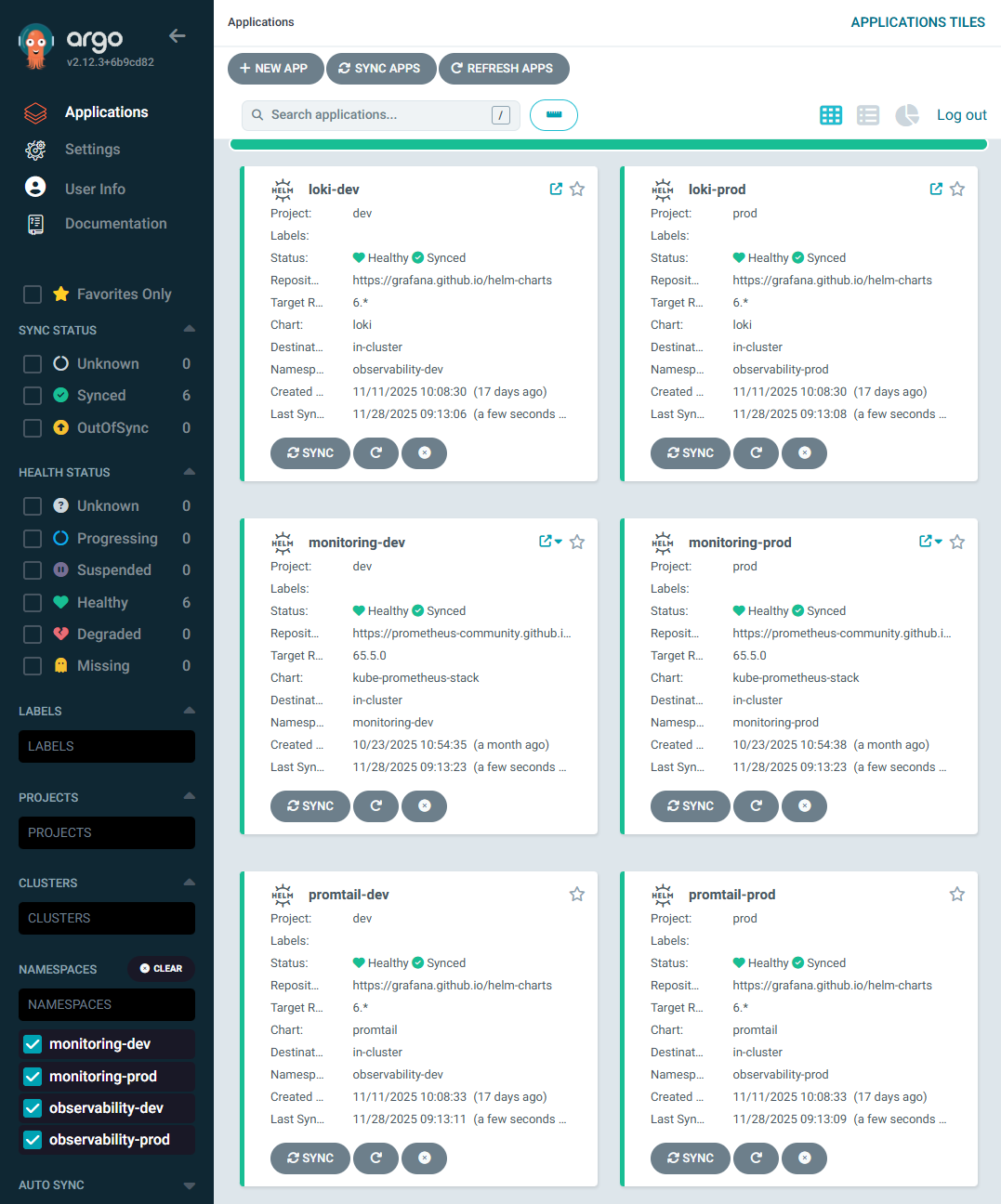
📸 proof-01-03-argocd-monitoring-observability.png
확인 포인트
monitoring-dev/prod,loki-dev/prod,promtail-dev/prod만 따로 필터링- Loki / Promtail / Prometheus 모두 Healthy + Synced
- dev / prod 네임스페이스가 완전히 분리된 상태로 운영
👉 결론: Observability 계층 전체가 환경별로 독립된 GitOps 관리를 받는 구조입니다.
2️⃣ Prometheus Targets (메트릭 수집 상태)
✔ 2-1. Prometheus(dev) Targets UI
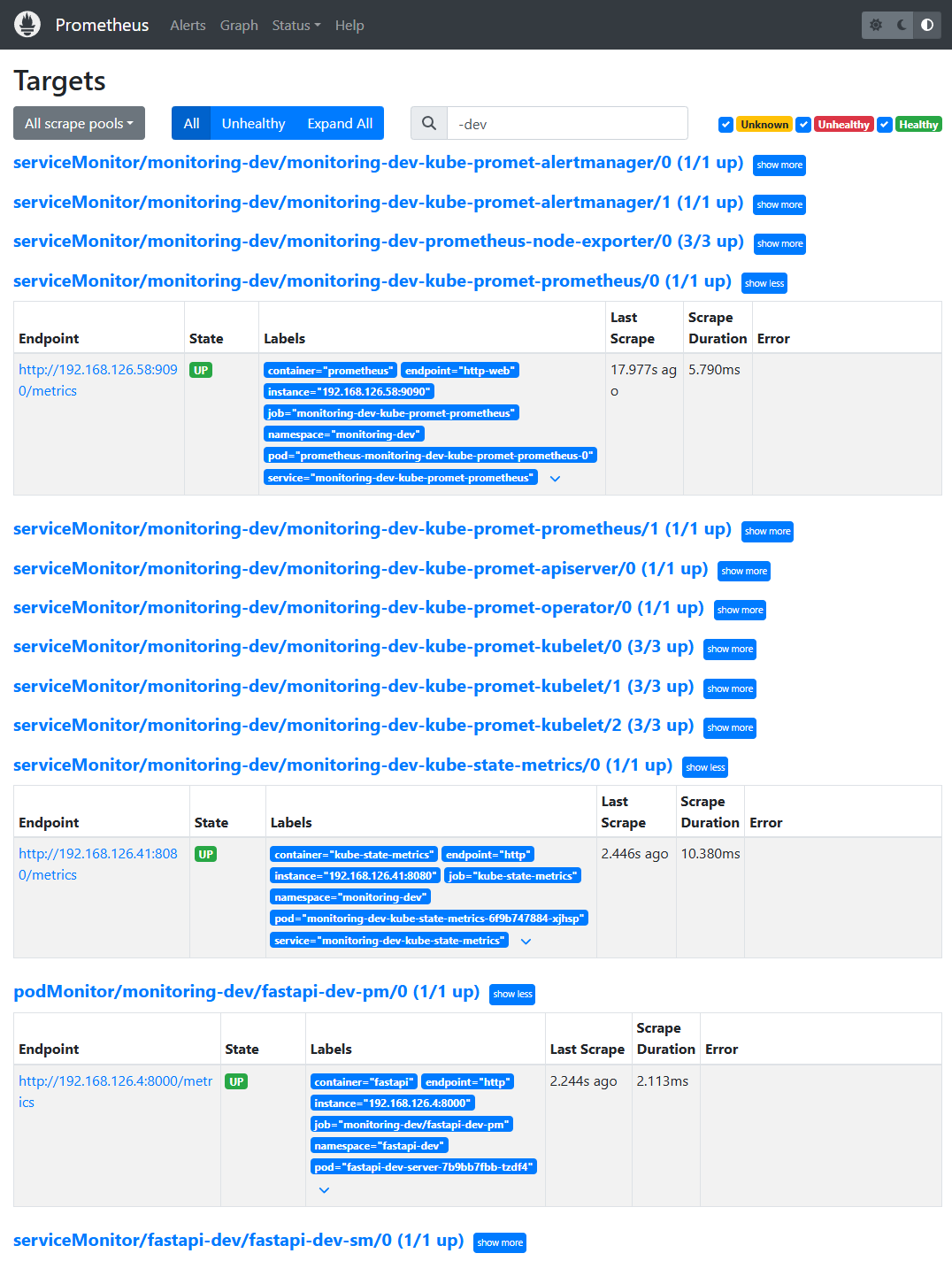
📸 proof-02-01-prometheus-dev-targets.png
확인 포인트
monitoring-dev-kube-promet-prometheus가 여러 ServiceMonitor를 정상 scrapealertmanager,node-exporter,kubelet,prometheus,apiserver,kube-state-metrics전부1/1 upFastAPI dev PodMonitor(
fastapi-dev-pm)의 메트릭도 정상 수집모든 namespace가
monitoring-dev로 일관
👉 결론: dev 환경에서 클러스터 핵심 지표 + FastAPI 지표를 모두 안정적으로 수집하고 있습니다.
✔ 2-2. Prometheus(prod) Targets UI
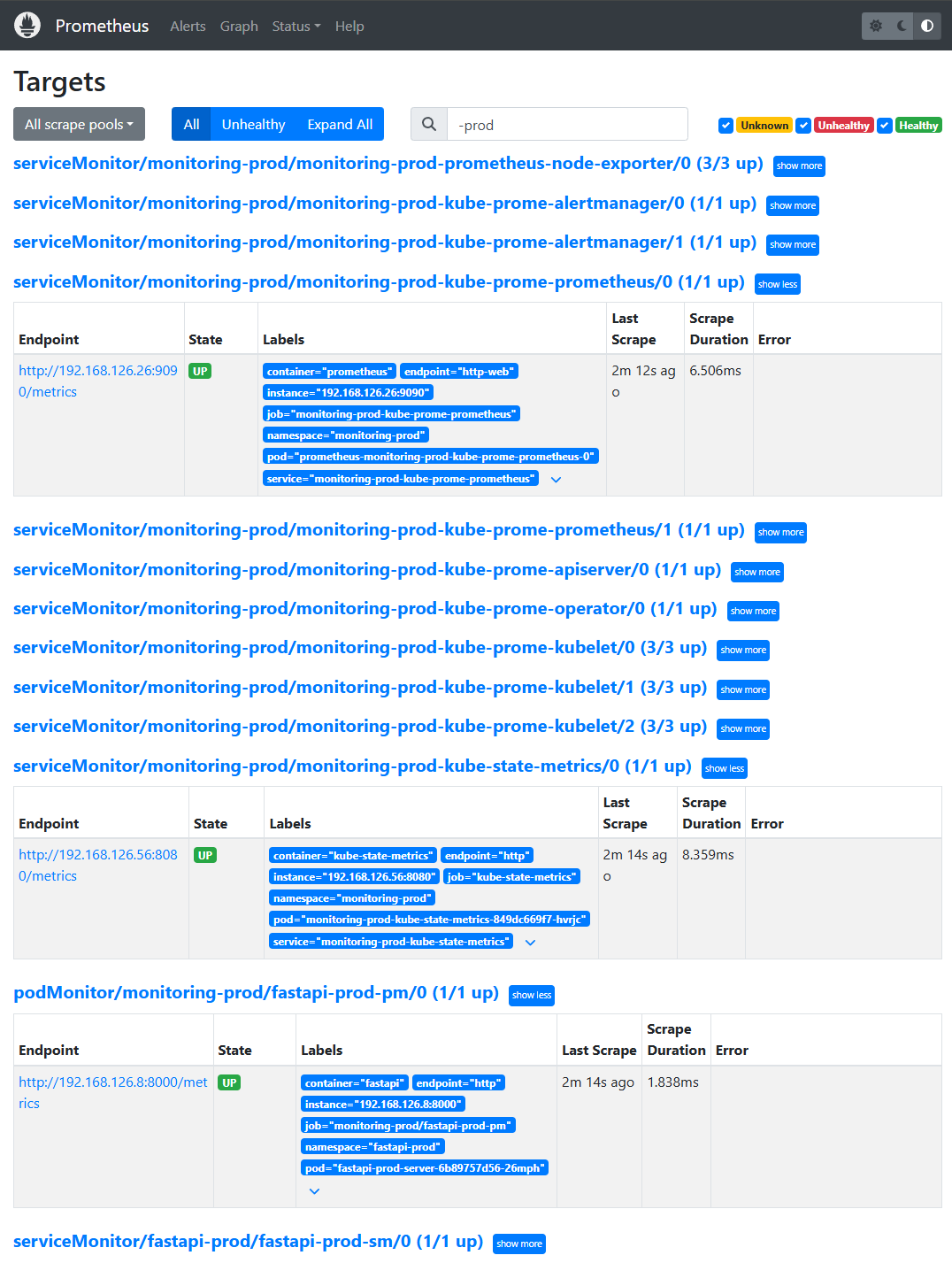
📸 proof-02-01-prometheus-prod-targets.png
확인 포인트
- prod 환경에서도 dev와 동일 구조의 Target이 모두
up fastapi-prod-pmPodMonitor 수집 정상- scrape duration 안정적
- 모든 namespace가
monitoring-prod로 고정
👉 결론: 운영(prod) Prometheus 인스턴스도 완전히 분리된 상태로
동일한 품질의 메트릭을 수집하고 있습니다.
✔ 2-3. CLI — ServiceMonitor & PodMonitor 목록
kubectl -n monitoring-dev get servicemonitor
kubectl -n monitoring-dev get podmonitor
kubectl -n monitoring-prod get servicemonitor
kubectl -n monitoring-prod get podmonitor
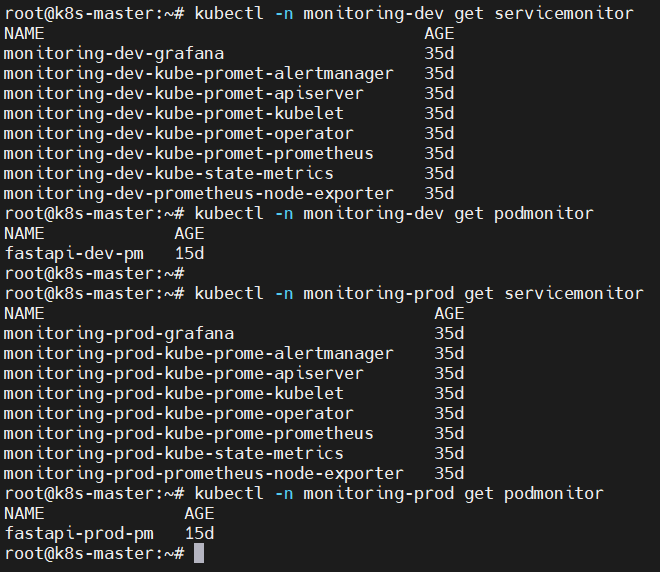
📸 proof-02-02-prometheus-dev-prod-target-cmd.png
확인 포인트
dev / prod 모두 동일한 ServiceMonitor 세트:
grafana, alertmanager, apiserver, kubelet, operator, prometheus,
kube-state-metrics, node-exporter
dev: fastapi-dev-pm, prod: fastapi-prod-pm PodMonitor 존재
👉 결론: Prometheus가 dev/prod에서 FastAPI 포함 모든 핵심 타겟을 안정적으로 scrape하고 있습니다.
3️⃣ Prometheus Alerts (알람 정의 및 발동)
✔ 3-1. FastAPI Alert Rule 정의
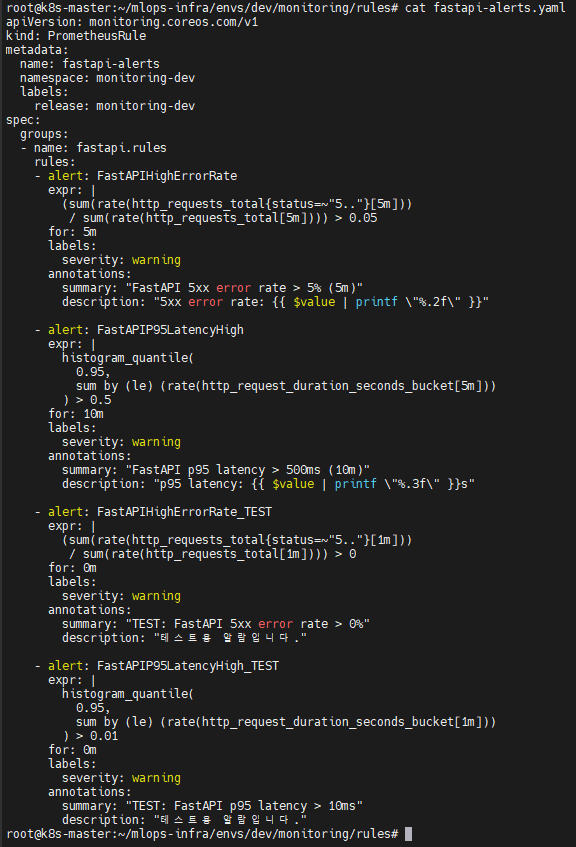
📸 proof-03-01-prometheus-fastapi-test-alert.png
확인 포인트
FastAPIHighErrorRate: 5xx error 비율 5% 초과 시 경고FastAPIP95LatencyHigh: p95 latency 500ms 초과 시 10분 동안 경고- 테스트용
_TEST규칙 2종 존재 (즉시 발동용) - summary / description annotation → 그대로 Slack 메시지 내용으로 사용
👉 결론: ML 서빙 API 관점에서 필수인 Error Rate / Latency 기반 SLO 알람이 완비되어 있습니다.
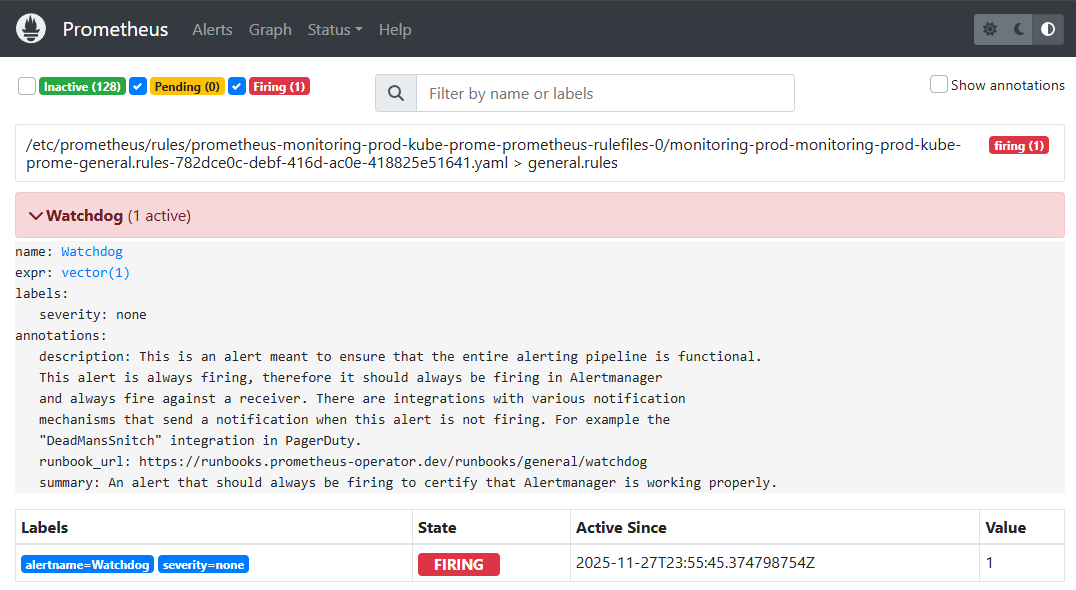
✔ 3-2. Prometheus(dev) Alerts — 알람 발동 확인
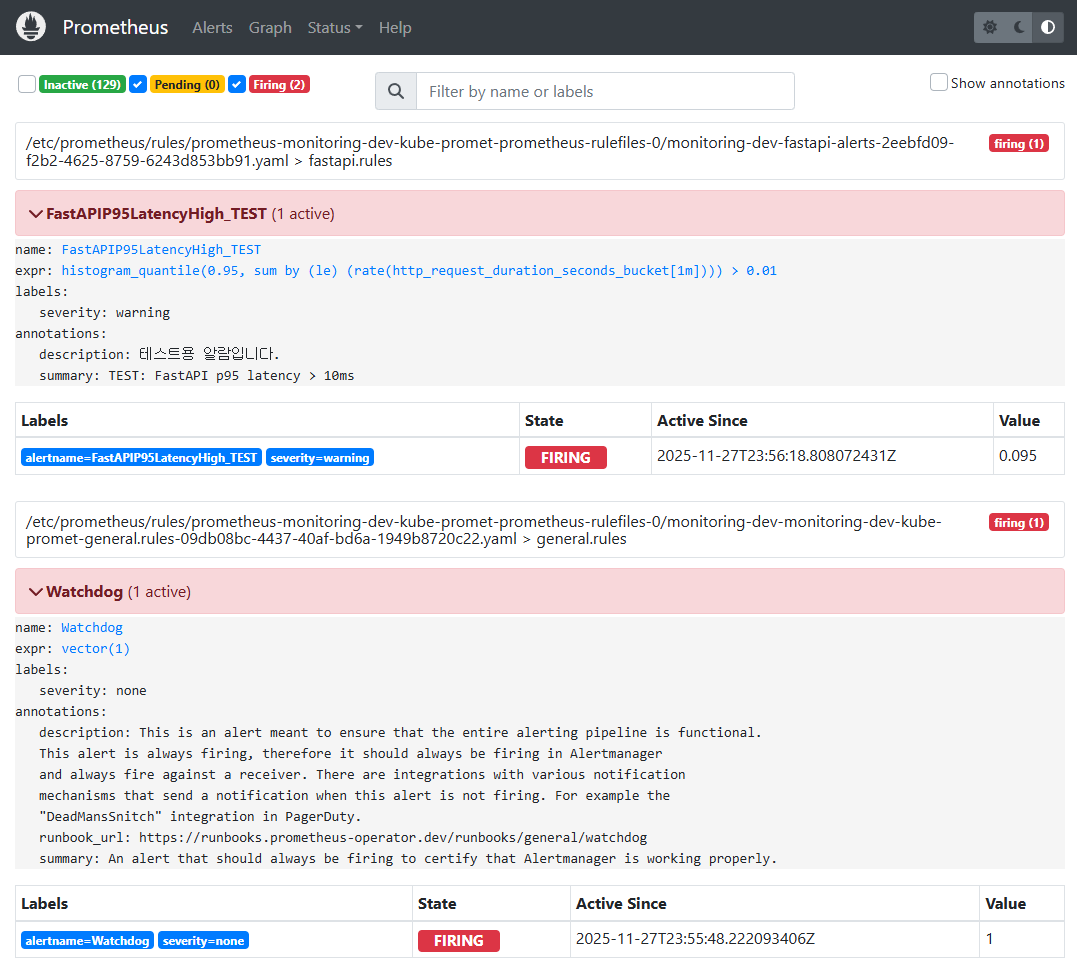
📸 proof-03-02-prometheus-dev-alert.png
확인 포인트
FastAPIP95LatencyHigh_TEST알람이 FIRING- Value, ActiveSince, expr(historgram_quantile) 정보가 정상 표시
Watchdog(vector(1))알람도 항상 FIRING 상태로 alert 파이프라인 헬스체크
👉 결론: dev Prometheus에서 Latency 알람 로직이 실제로 동작하고 있습니다.
✔ 3-3. Slack(dev) — 알람 수신
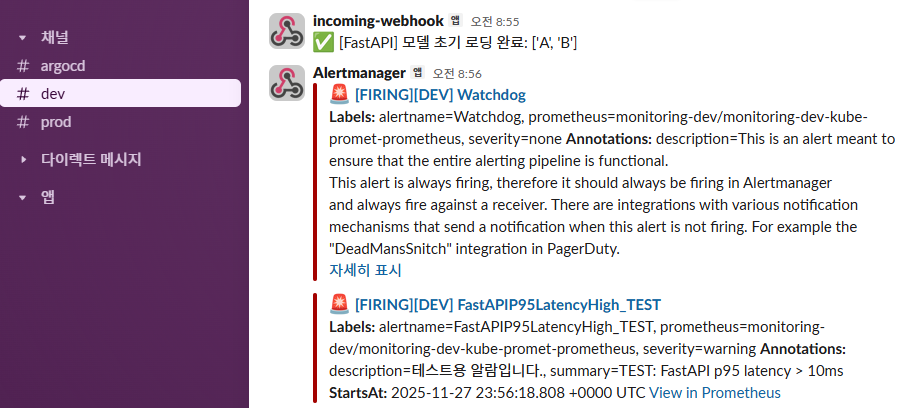
📸 proof-03-02-prometheus-dev-alert-slack.png
확인 포인트
[FIRING][DEV] FastAPIP95LatencyHigh_TEST,Watchdog메시지 도착- alertname / severity / summary / description / timestamp 그대로 매핑
- dev 채널로만 도착
👉 결론: Prometheus → Alertmanager → Slack(dev) 의 엔드투엔드 알람 체인이 정상입니다.
✔ 3-4. Prometheus(prod) Alerts & Slack(prod)
📸 proof-03-02-prometheus-prod-alert.png

📸 proof-03-02-prometheus-prod-alert-slack.png
확인 포인트
- prod 환경에서도 Watchdog FIRING 상태 유지
- Alertmanager(prod) → Slack(prod) 전용 라우팅
- dev 알람이 prod 채널로 섞여 들어오지 않음
👉 결론: dev / prod 모두 환경 분리된 알람 시스템을 갖추고 있습니다.
4️⃣ Alertmanager Config (dev/prod 분리)
✔ 4-1. Alertmanager(dev) 상태 및 설정
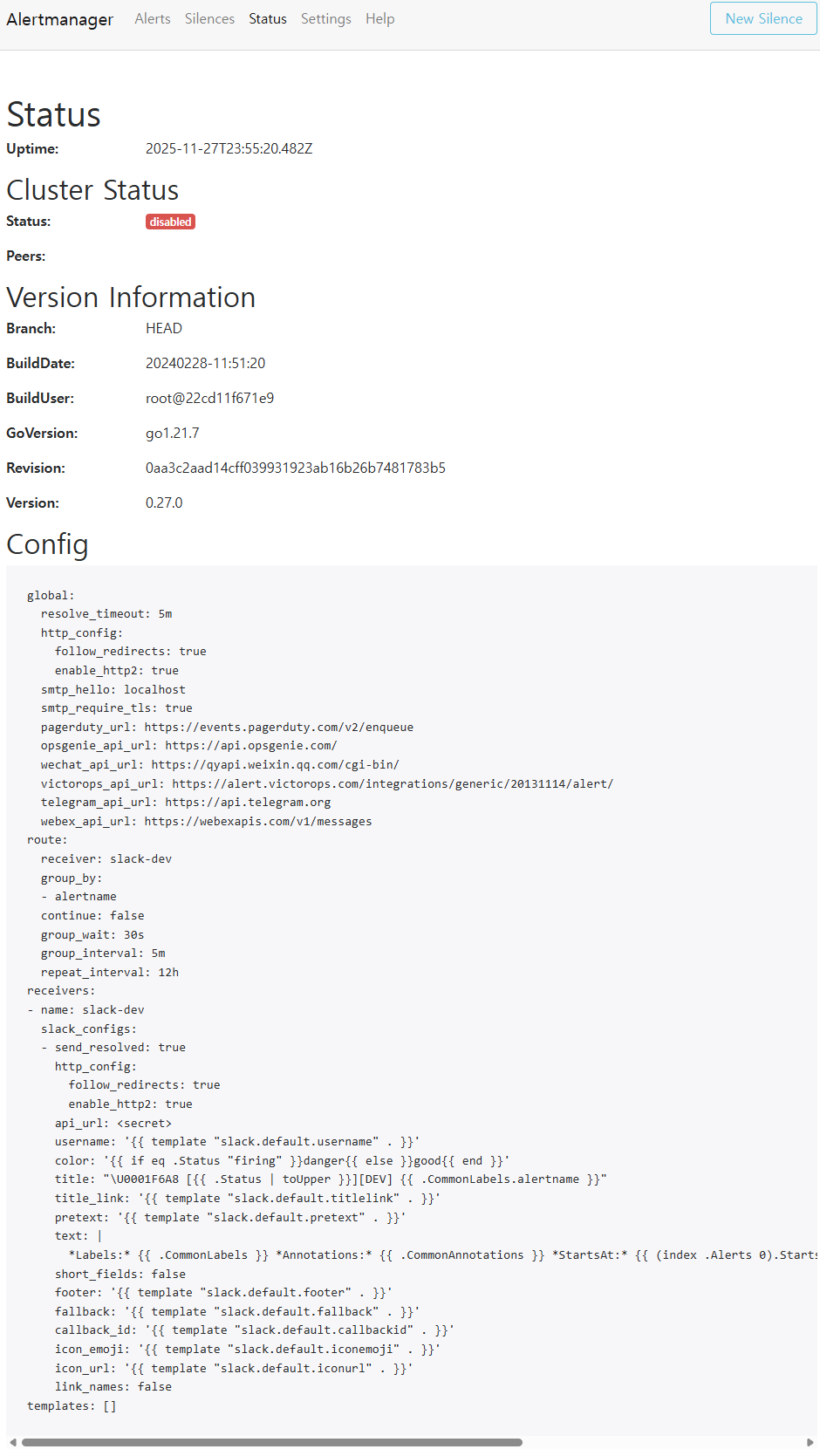
📸 proof-04-01-alertmanager-dev-status.png
확인 포인트
- cluster: disabled (single 구성)
- route.receiver = slack-dev
- Slack 템플릿 / 색상 / footer / send_resolved=true 설정
- group_wait 30s / group_interval 5m / repeat_interval 12h
- 향후 PagerDuty/Telegram/Webex 로 확장 가능한 구조
👉 결론: dev 환경 전용 Alertmanager 구성이 안정적으로 동작 중입니다.
✔ 4-2. Alertmanager(prod) 상태 및 설정
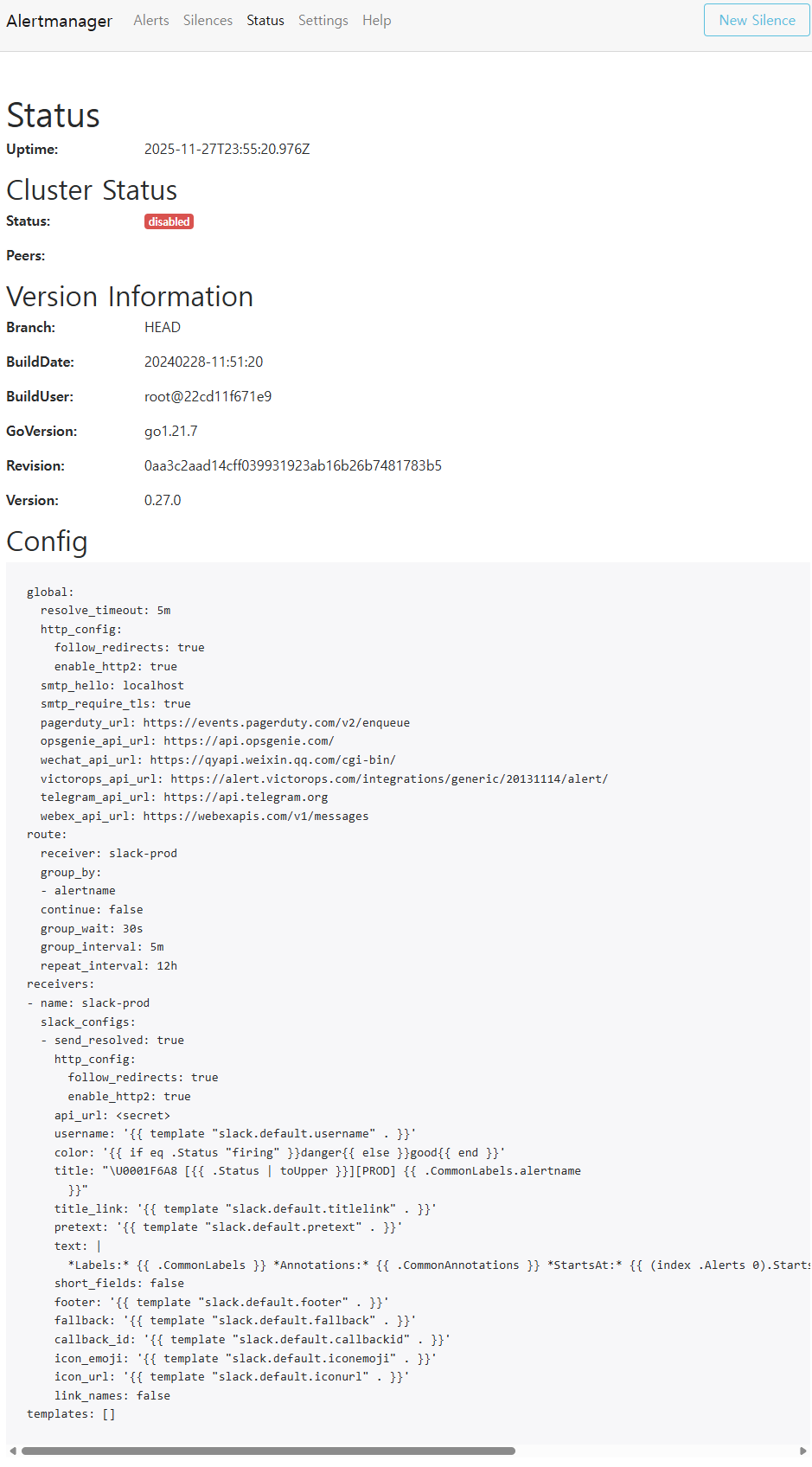
📸 proof-04-01-alertmanager-prod-status.png
확인 포인트
- route.receiver = slack-prod
- dev와 다른 Slack webhook & 템플릿
- 동일 rule 구조지만 완전히 다른 알람 라우팅
👉 결론: prod 환경은 운영용 Slack(prod)만 사용하는 안정적 알람 채널을 갖고 있습니다.
✔ 4-3. Alertmanager Secret YAML(dev/prod)

📸 proof-04-02-alertmanager-dev-secret-cmd.png
📸 proof-04-02-alertmanager-prod-secret-cmd.png
확인 포인트
- dev :
alertmanager-monitoring-dev-kube-promet-alertmanager - prod :
alertmanager-monitoring-prod-kube-prome-alertmanager - type: Opaque, namespace dev/prod 분리
- 내부에 base64 인코딩된
alertmanager.yaml저장
👉 결론: Alertmanager 설정 값이 쿠버네티스 Secret으로 안전하게 관리되고 있습니다.
✔ 4-4. Alertmanager Alerts 페이지(dev/prod)
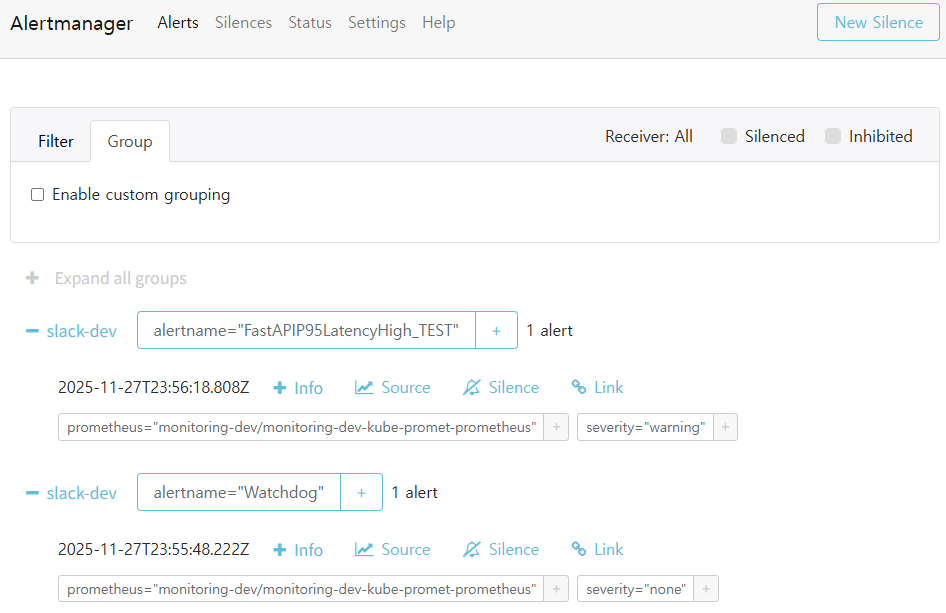
📸 proof-04-03-alertmanager-dev-alerts.png
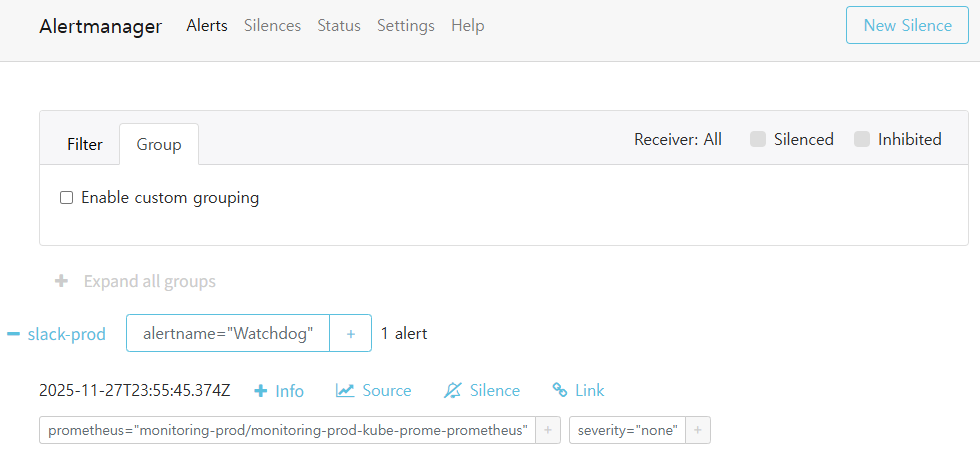
📸 proof-04-03-alertmanager-prod-alerts.png
확인 포인트
- dev: slack-dev 그룹에
FastAPIP95LatencyHigh_TEST,Watchdog표시 - prod: slack-prod 그룹에
Watchdog1건 FIRING - severity, source, 시작시간, 라벨이 그대로 표시됨
👉 결론: 두 환경 모두 Alertmanager 레벨에서도 그룹·라우팅이 정확히 분리됩니다.
5️⃣ Loki 로그 (FastAPI 로그 수집)
✔ 5-1. Grafana Explore — FastAPI(dev) 로그
쿼리:
{namespace="fastapi-dev"}
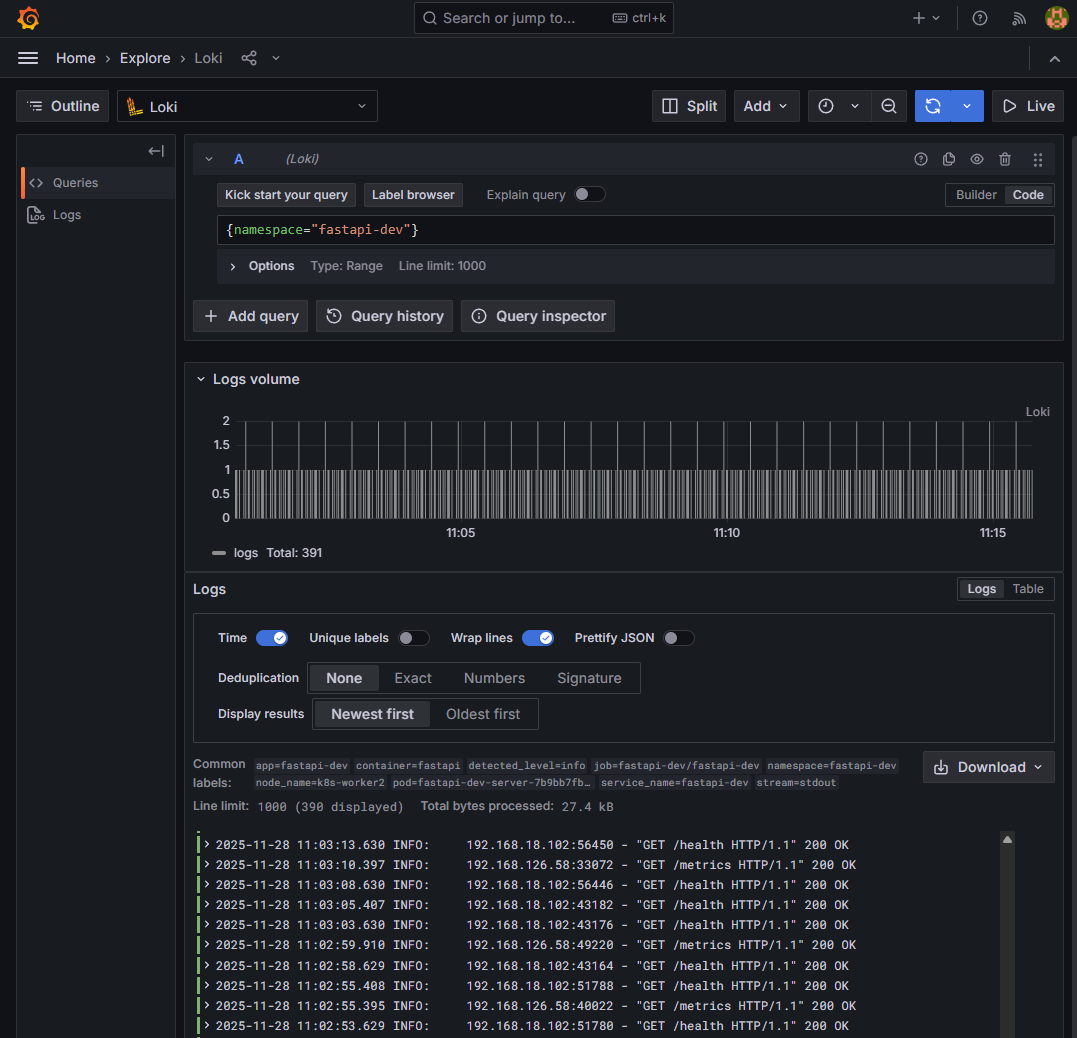
📸 proof-05-01-grafana-dev-explore-fastapi-dev.png
확인 포인트
- GET
/metrics,/health,/predict로그 연속 출력 service_name=fastapi-dev,container=fastapi라벨 정상- JSON prettify 시에도 파싱 오류 없음
👉 결론: FastAPI(dev) → Promtail → Loki → Grafana 로그 파이프라인이 온전히 작동합니다.
✔ 5-2. Grafana Explore — FastAPI(prod) 로그
{namespace="fastapi-prod"}
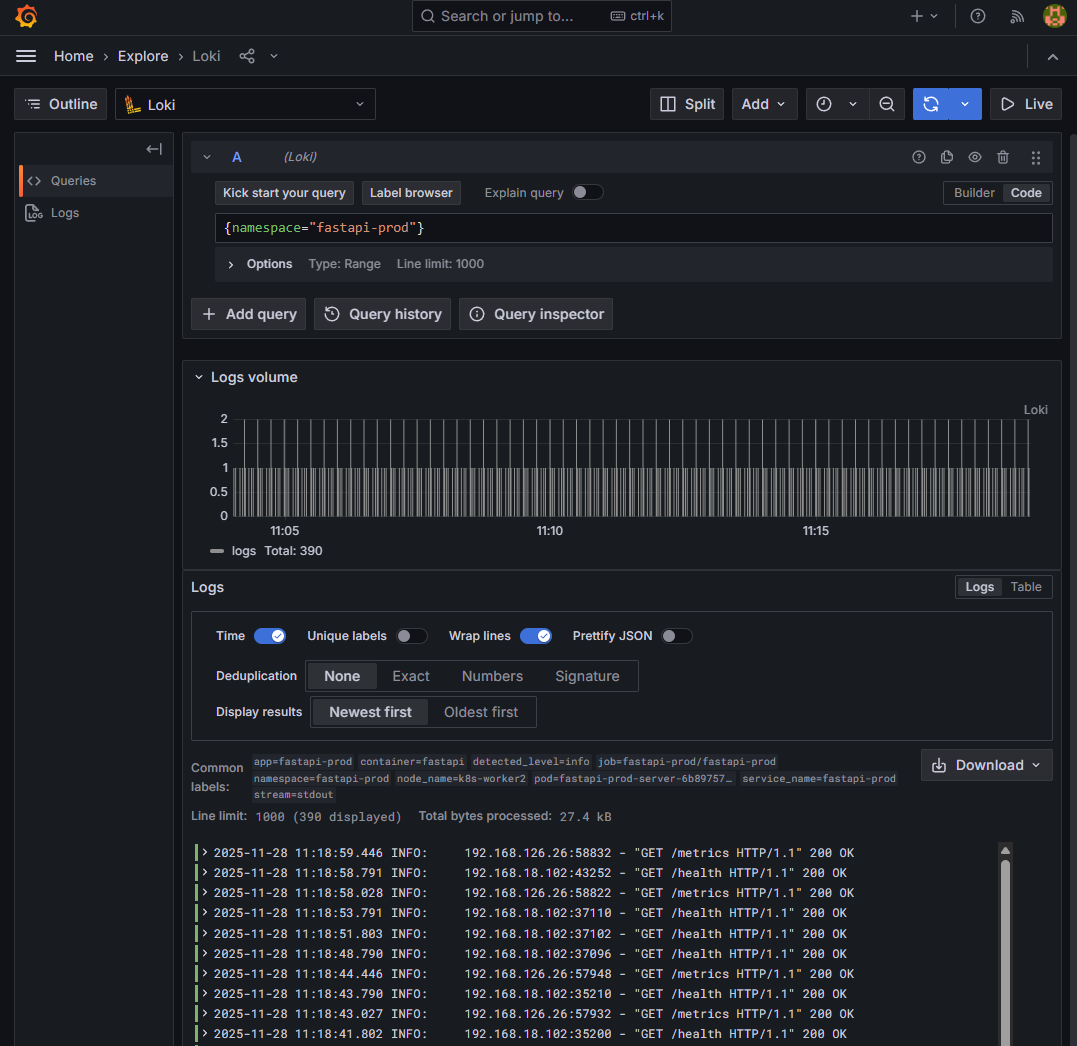
📸 proof-05-01-grafana-prod-explore-fastapi-prod.png
확인 포인트
- dev와 분리된 log stream
- Node / Pod 라벨이 prod 기준으로 별도 수집
- 로그 수집량이 dev와 독립적으로 누적
👉 결론: prod 환경에서도 FastAPI 로그가 완전히 분리된 Loki 인스턴스로 수집됩니다.
✔ 5-3. Loki Pod 로그(dev/prod)
# dev
kubectl get pod -n observability-dev
kubectl -n observability-dev logs loki-dev-0 | head
# prod
kubectl get pod -n observability-prod
kubectl -n observability-prod logs loki-prod-0 | head
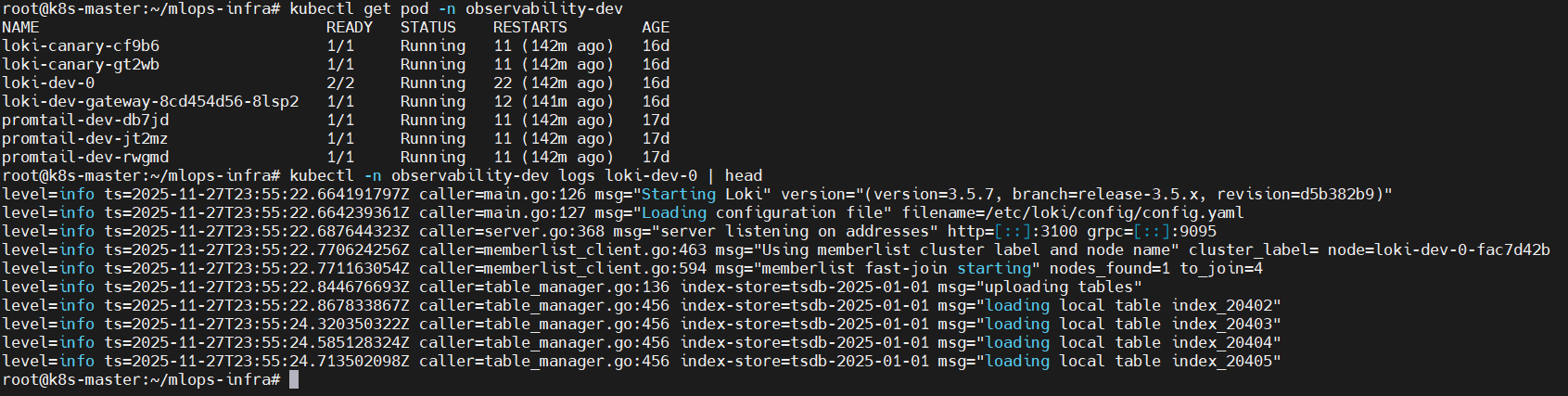
📸 proof-05-02-loki-dev-logs-cmd.png
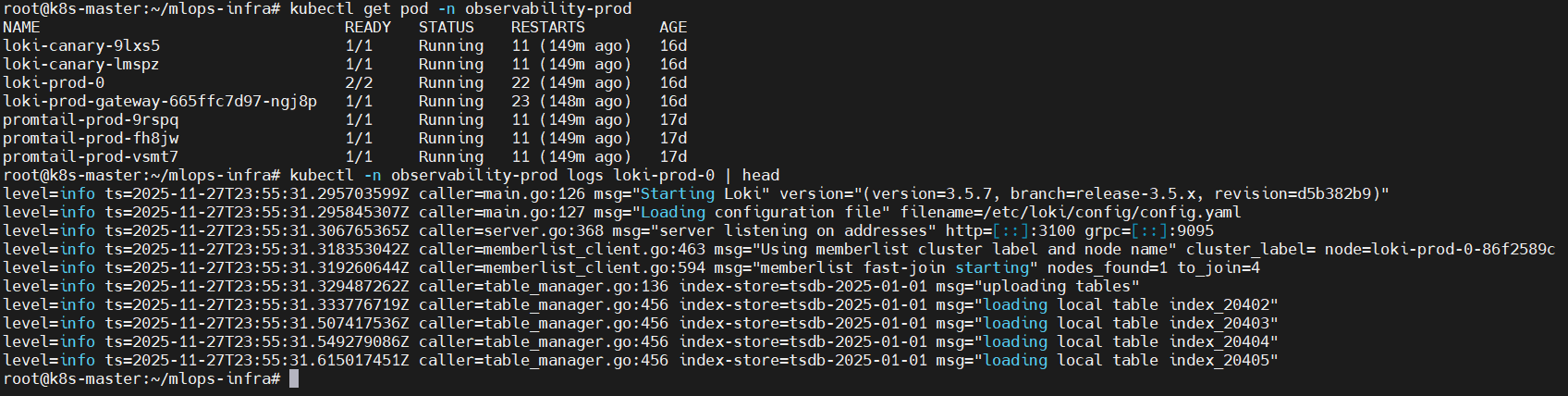
📸 proof-05-02-loki-prod-logs-cmd.png
확인 포인트
- Loki 버전/리비전 표기, config load 정상
server listening on addresses로그로 HTTP/gRPC 포트 활성화 확인- TSDB index table 로딩 메시지 정상
👉 결론: dev / prod Loki 인스턴스 모두 정상 부팅 및 스토리지 초기화를 완료합니다.
6️⃣ Slack 알람 Smoke 테스트 (알람 체인 E2E 검증)
✔ 6-1. Smoke Alert PrometheusRule 생성
cat <<'EOF' | kubectl -n monitoring-dev apply -f -
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: alertmanager-smoke
labels:
release: monitoring-dev
spec:
groups:
- name: smoke.rules
rules:
- alert: Smoke_Alert_To_Slack
expr: vector(1)
for: 1m
labels:
severity: warning
namespace: monitoring-dev
annotations:
summary: "Smoke test alert"
description: "This is a test alert to verify Slack integration"
EOF
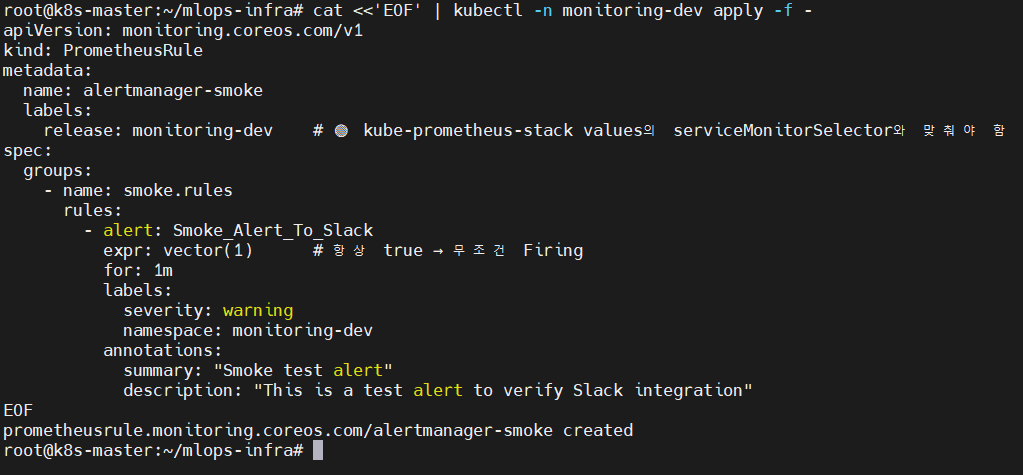
📸 proof-06-01-smoke-prometheusRule-dev.png
👉 결론: 항상 true인 vector(1) 기반으로, 항상 Firing 상태가 유지되는 Smoke Alert를 정의했습니다.
✔ 6-2. Prometheus Alerts에서 Smoke Alert FIRING
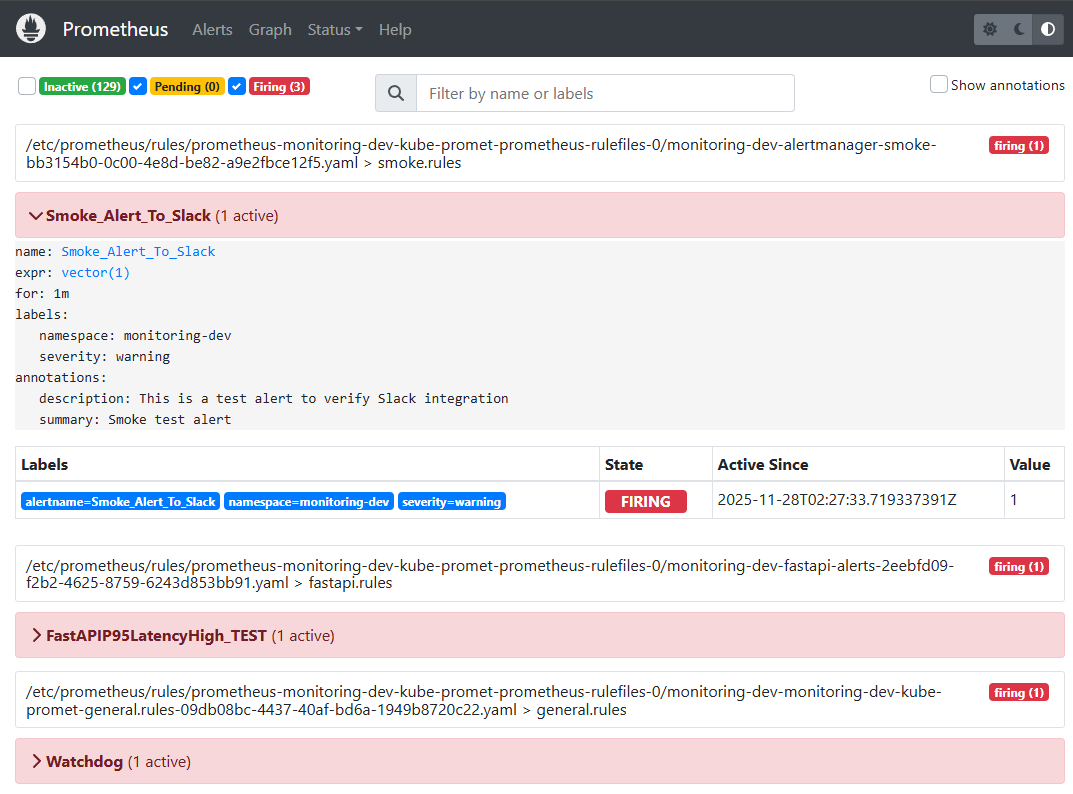
📸 proof-06-02-prometheus-dev-alerts-smoke.png
확인 포인트
- alertname:
Smoke_Alert_To_Slack - expr:
vector(1) - labels:
namespace=monitoring-dev,severity=warning State = FIRING,Value = 1
✔ 6-3. Alertmanager 그룹 — slack-dev 라우팅
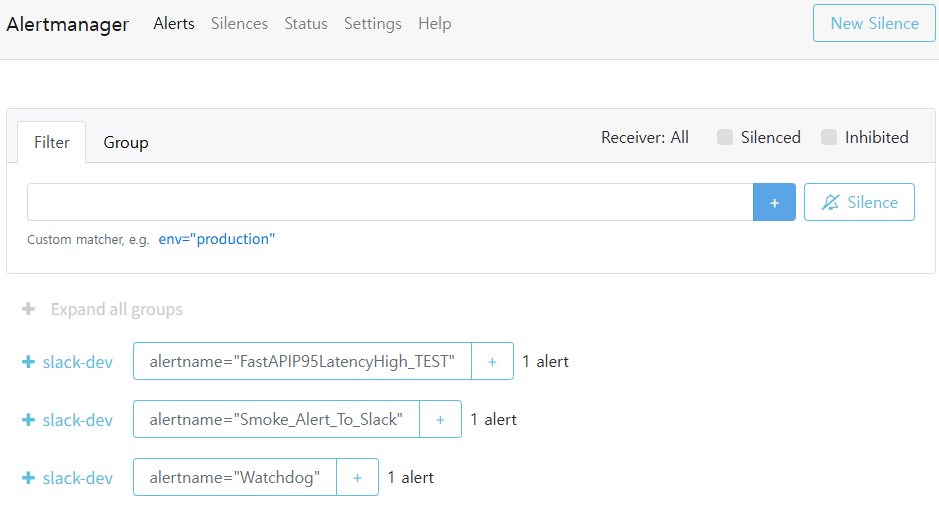
📸 proof-06-03-alertmanager-dev-alerts-smoke.png
확인 포인트
- 그룹명:
slack-dev Smoke_Alert_To_Slack,FastAPIP95LatencyHigh_TEST,Watchdog가 같은 그룹으로 라우팅- Alertmanager가 여러 Alert를 하나의 Slack 채널로 묶어 전송하는 구조
✔ 6-4. Slack #dev 채널 — Smoke Alert 수신
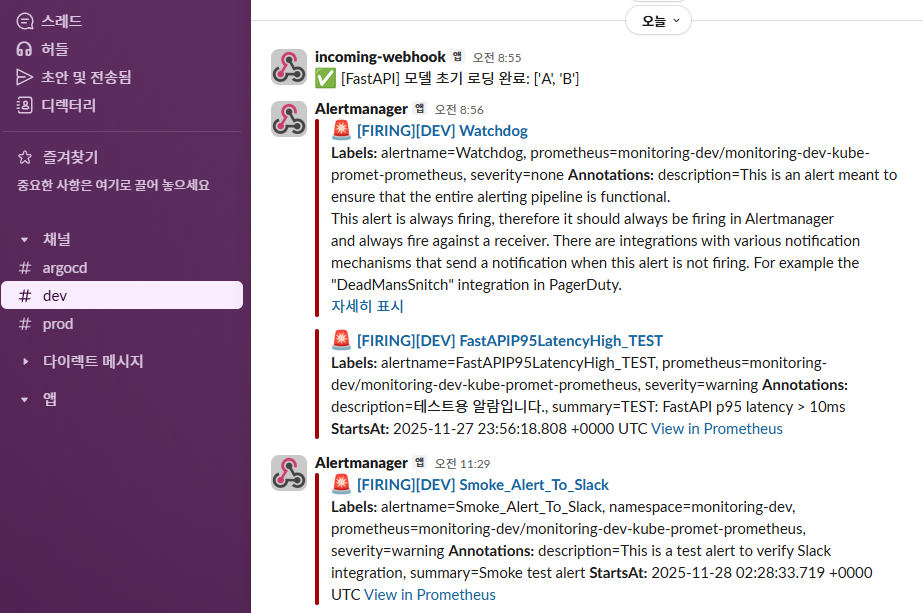
📸 proof-06-04-slack-dev-alerts-smoke.png
확인 포인트
[FIRING][DEV] Smoke_Alert_To_Slack메시지 도착- alertname / namespace / severity 라벨 그대로 표시
- 기존 FastAPI 테스트 알람들과 함께 dev 채널에 쌓임
✔ 6-5. Prometheus / Alertmanager API 결과 확인
# Prometheus
curl -sk https://prometheus-dev.local/api/v1/alerts \
| jq '.data.alerts[] | select(.labels.alertname=="Smoke_Alert_To_Slack") | {state:.state, labels:.labels}'
# Alertmanager
curl -sk https://alert-dev.local/api/v2/alerts \
| jq '.[] | select(.labels.alertname=="Smoke_Alert_To_Slack") | {status:.status, receiver:.receiver.name}'
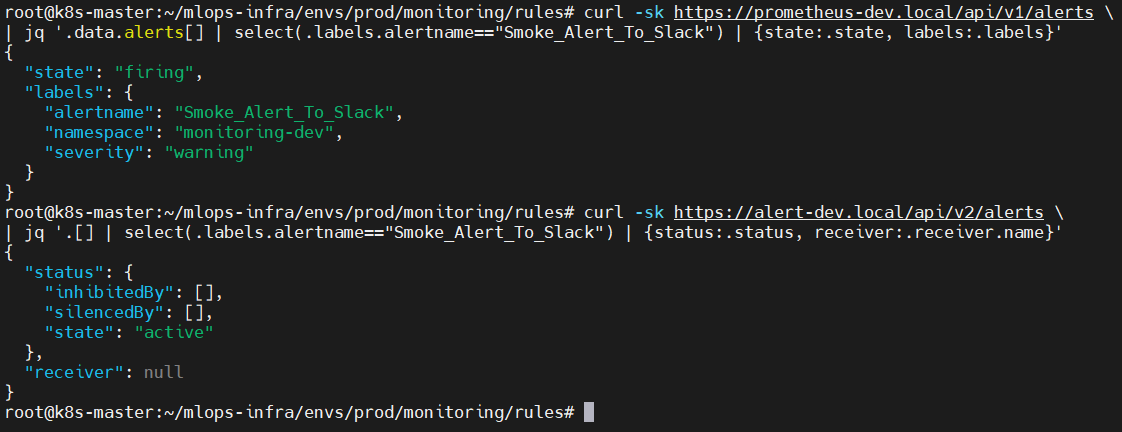
📸 proof-06-05-prometheus-alertmanager-cmd.png
결과 요약
- Prometheus:
"state": "firing" - Alertmanager:
"status.state": "active","receiver": "slack-dev"
👉 최종 결론: PrometheusRule → Prometheus → Alertmanager → Slack(dev)까지
알람 체인 전체가 안정적으로 동작함을 Smoke Alert로 증명했습니다.
7️⃣ Platform - Kubernetes & Nodes 대시보드
FastAPI 알람이 발생했을 때,
문제가 API 자체인지, 플랫폼(Kubernetes)인지를 즉시 분리하기 위해
클러스터 전반을 한 번에 확인할 수 있는 플랫폼 대시보드를 추가 구성했습니다.
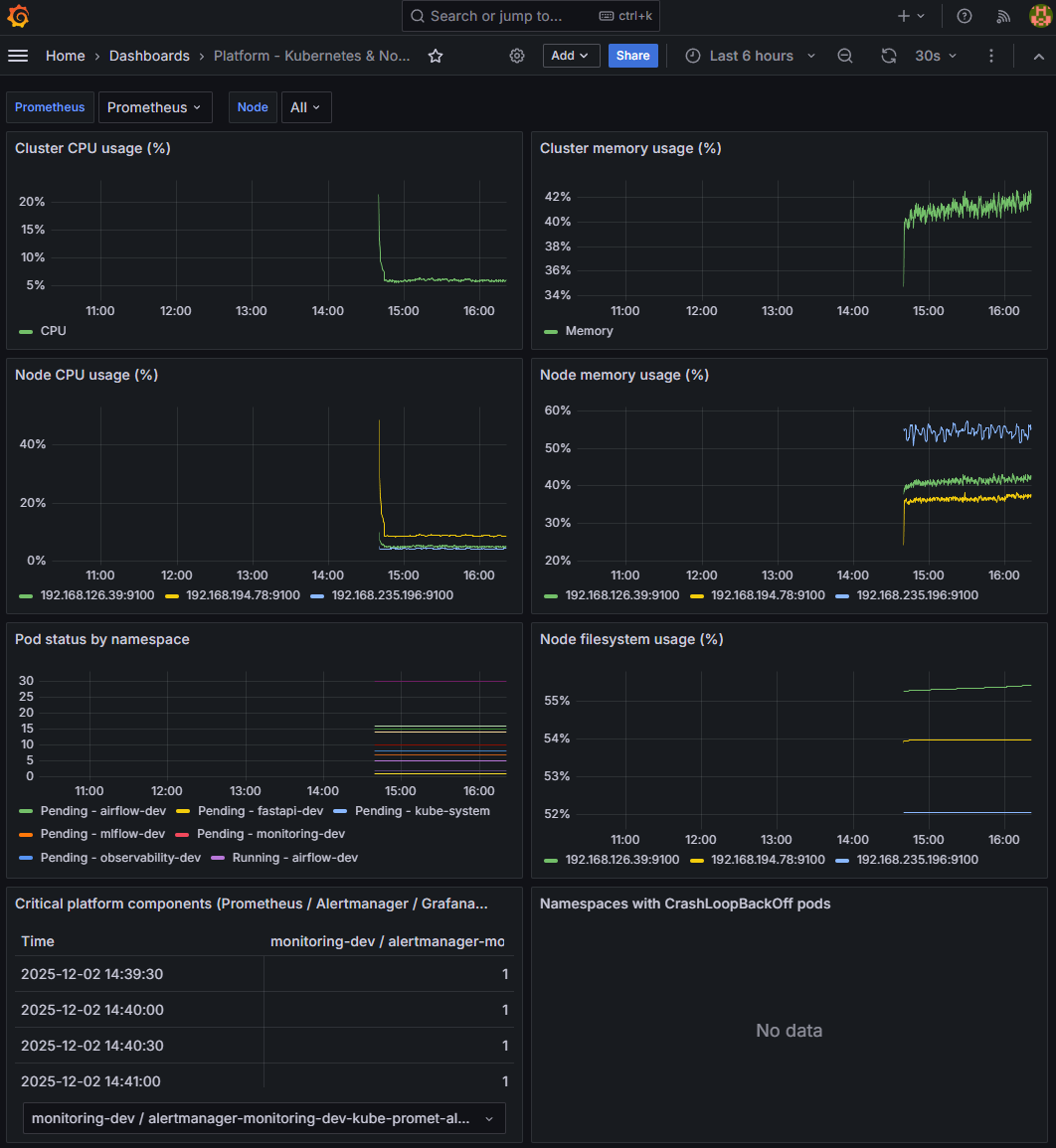
📸 proof-07-01-kube-platform-overview.png
(클러스터 CPU/메모리 → Node별 사용률 → Pod 상태 → 모니터링 스택 헬스까지 한 화면에 표시)
✔ 주요 확인 포인트
- Cluster 자원 사용률(CPU/Memory)
- 클러스터 전체 레벨에서 CPU/메모리 병목 여부 확인 → FastAPI 지연의 원인이 “전체 자원 부족”인지 빠르게 분리 가능
- Node별 CPU · Memory · Filesystem 사용률
- 특정 노드만 자원이 몰리는지 확인 → Pod 스케줄링 불균형, 디스크 Full 이슈 즉시 파악
- Pod 상태(Pending / Failed / CrashLoopBackOff)
- 배포 이후 Pending/CrashLoopBackOff 발생 시 즉시 확인 → FastAPI 문제인지, Node/Storage 문제인지 구분
- 모니터링 스택(Prometheus / Alertmanager / Grafana / Loki) 헬스체크
- “메트릭이 안 보이는 게 FastAPI 때문인지, 모니터링 스택 문제인지” 바로 판단 가능
👉 결론
FastAPI에서 5xx가 발생해도, 실제 원인은
- Prometheus scrape 실패
- Loki 로그 적재 지연
- Node CPU/메모리 포화
- NFS I/O 병목
- CrashLoopBackOff 등
플랫폼 문제일 수 있습니다.
이 플랫폼 대시보드를 통해 “애플리케이션 vs 플랫폼” 원인 분리를 빠르게 수행할 수 있으며,
dev/prod로 완전히 분리된 Observability 스택이 작동함을 증명합니다.
B. FastAPI Observability & Grafana 대시보드
FastAPI 애플리케이션이 실제 트래픽을 받고,
Prometheus → Grafana → Loki → Alertmanager → Slack까지
End-to-End Observability가 제대로 작동함을 증명합니다.
1️⃣ FastAPI 성능 부하 테스트(hey) → 메트릭 반영
✔ 1-1. hey 부하 테스트 (20초 / q 5 / c 10)
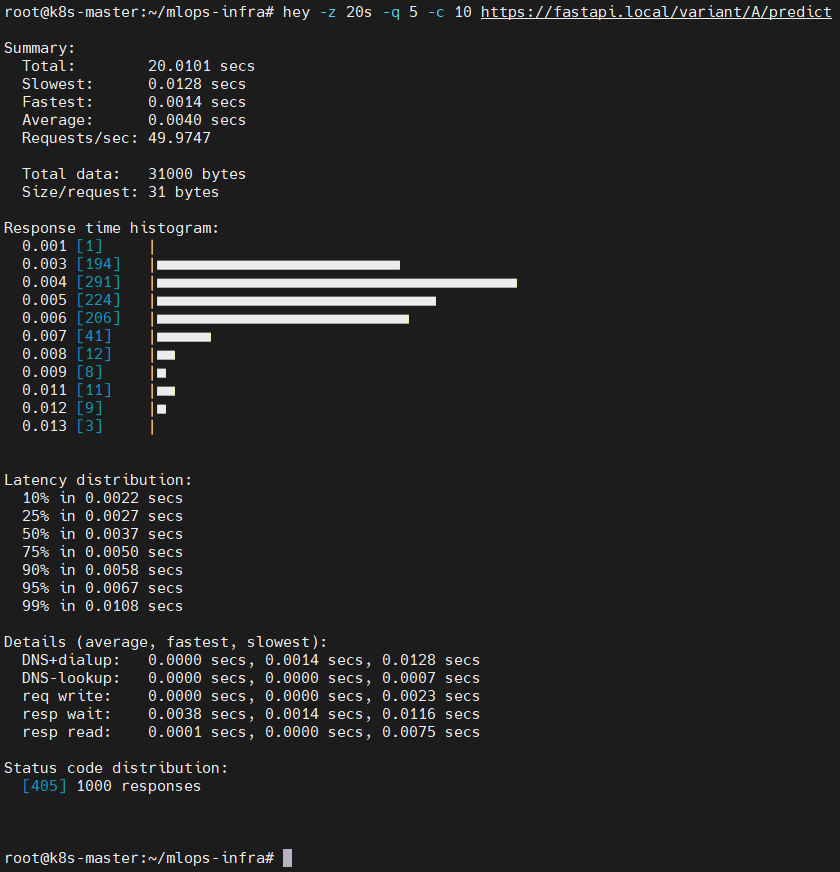
📸 proof-01-fastapi-dev-hey-test.png
확인 포인트
- 20초 동안 초당 약 49 req/s 처리
- 평균 latency ≈ 4ms, p99 ≈ 10ms
- HTTP 405는
/predict엔드포인트가 GET 미지원이라 발생하지만 FastAPI는 정상 동작
👉 결론: FastAPI 앱의 기본 성능과 안정성이 충분함을 보여줍니다.
2️⃣ Grafana 대시보드 — RPS / Latency 실시간 반영
✔ 2-1. hey 트래픽 → RPS 반영
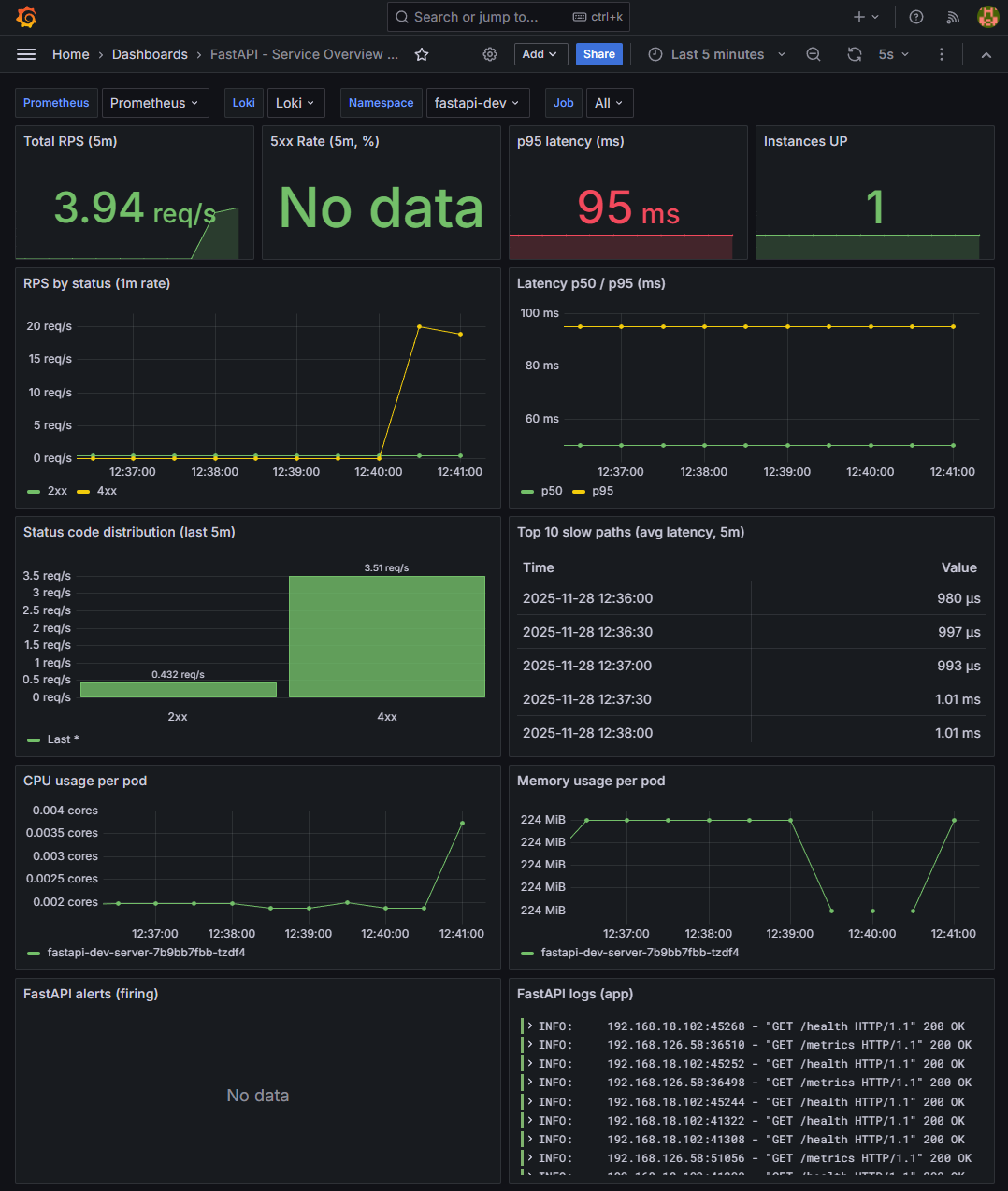
📸 proof-01-grafana-dev-hey-test.png
확인 포인트
- Total RPS(5m)가 hey 부하 시점에 맞춰 상승 후 안정
- RPS by status (2xx / 4xx) 분포 정상 표시
👉 결론: FastAPI 메트릭이 Prometheus → Grafana로 실시간 반영됩니다.
✔ 2-2. p50 / p95 latency 그래프
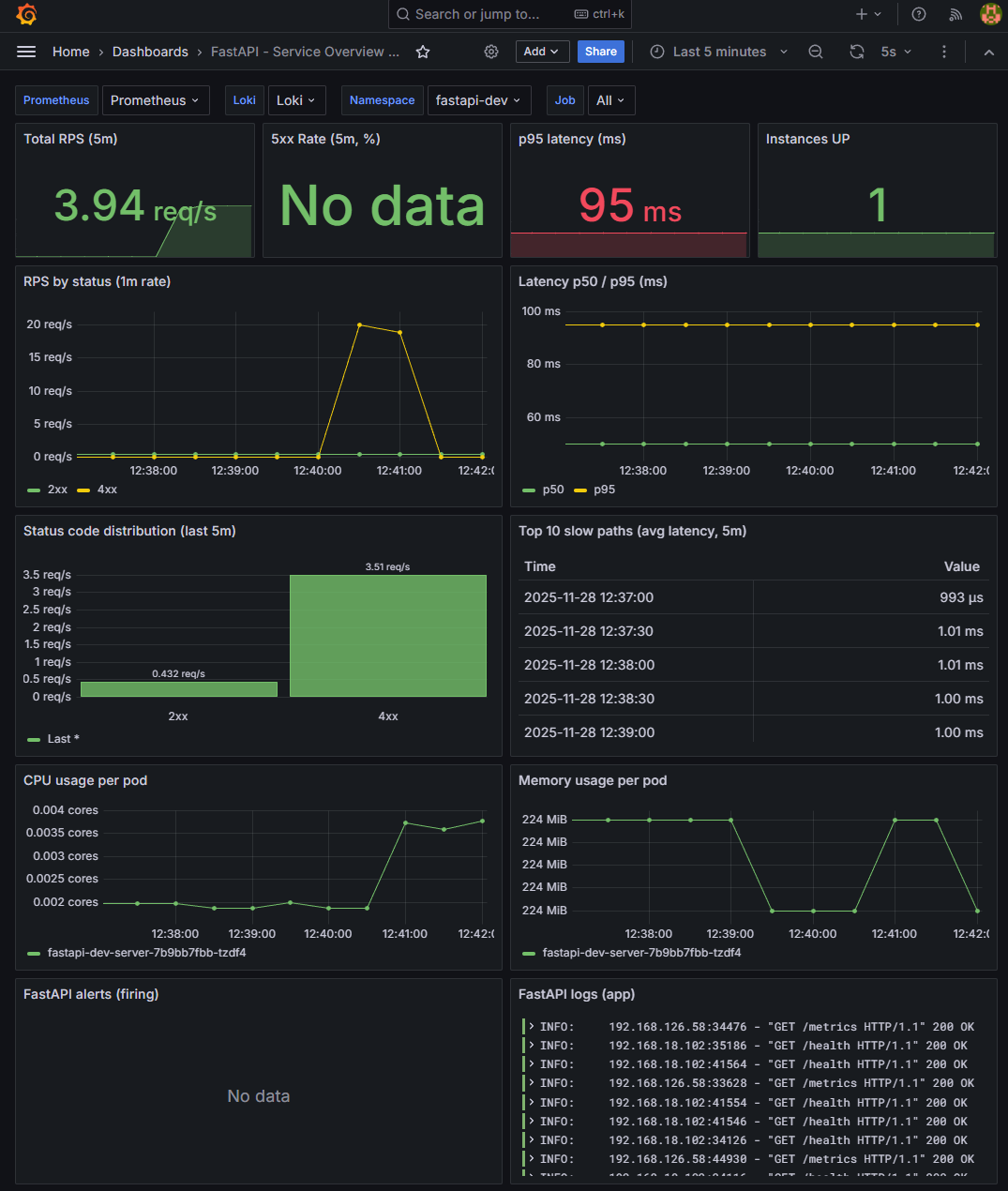
📸 proof-01-grafana-dev-hey-test-2.png
확인 포인트
- p50 / p95 latency 라인이 hey 부하 구간에도 안정적으로 유지
- histogram 기반 계산식이 정상 동작
👉 결론: Latency 기반 Alert Rule의 근거 데이터가 제대로 수집되고 있습니다.
✔ 2-3. FastAPI A/B & Model Deep Dive 대시보드 (http_* only)
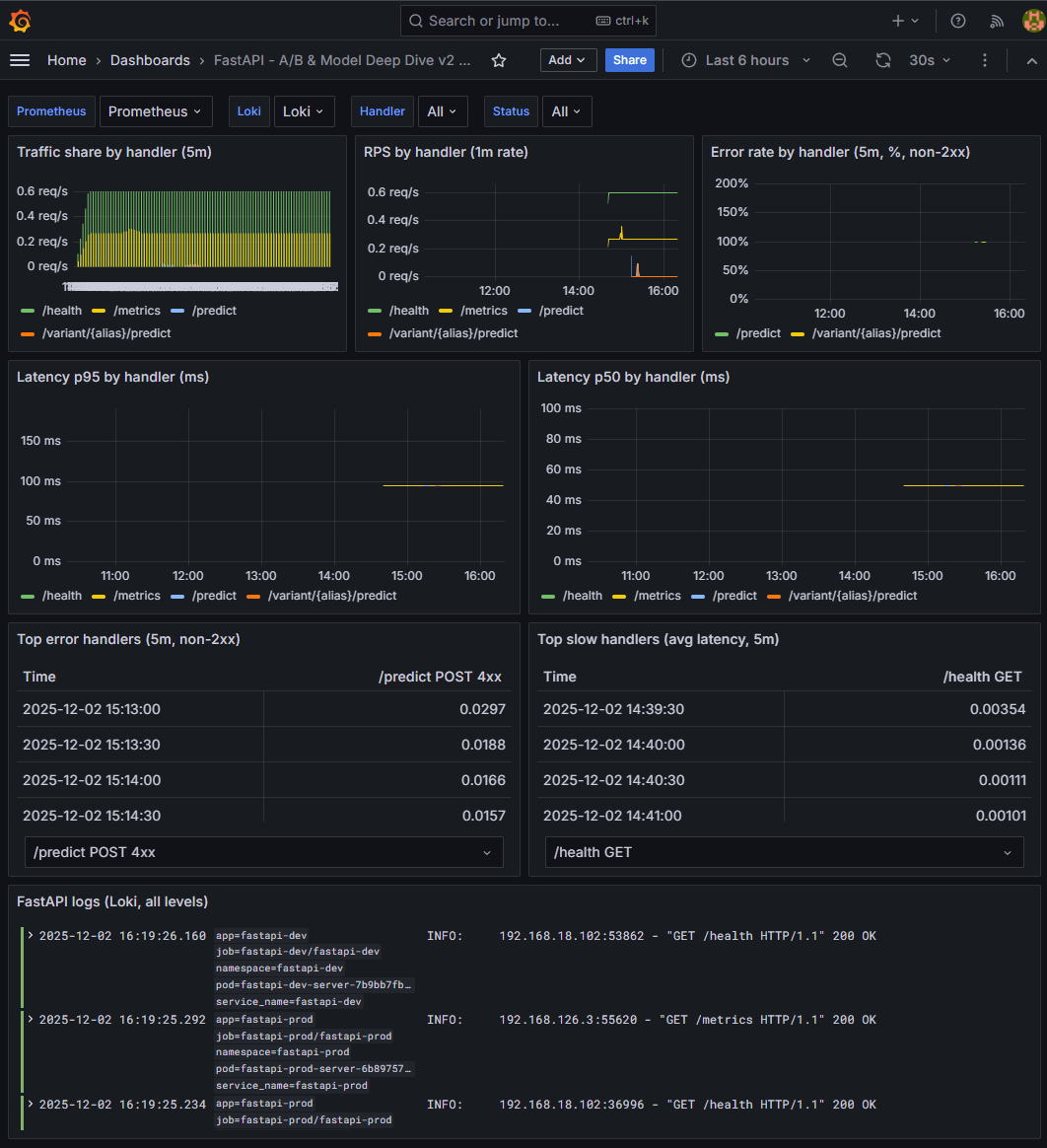
📸 proof-02-03-fastapi-deepdive-main.png
확인 포인트(요약 중심)
- 템플릿 변수
handler:/health,/metrics,/predict,/variant/{alias}/predict등 선택status:2xx,4xx,5xx상태코드 필터링
상단: 트래픽 / 에러율
Traffic share by handler (5m)
→ 최근 트래픽이 어떤 엔드포인트에 몰렸는지 비중으로 확인
RPS by handler (1m)
→ 1분 단위 RPS 변화로 특정 엔드포인트 스파이크 감지
5xx rate by handler (5m)
→ 현재는 5xx 발생이 없어 빈 상태
→ 테스트로 오류를 유도하면 어떤 핸들러가 실패하는지 즉시 파악 가능
중단: 핸들러별 Latency(p50/p95)
Latency p95
→ tail latency. 모델 교체 후 특정 alias(
A/B)가 느려지는지 감지Latency p50
→ 전체 평균 성능
→ p50 대비 p95가 크게 튀면 “일부 요청만 느린 상황(tail)”을 의미
하단: 에러 & 슬로우 핸들러
Top error handlers (5m)
→
/predict POST 4xx등, 최근 5분 간 오류가 가장 많은 조합을 정렬→ 입력 오류(422), 모델 오류(500) 어디서 터졌는지 즉시 확인
Top slow handlers (avg latency, 5m)
→ 평균 latency 기준 상위 10개 엔드포인트
→
variant/Avsvariant/B응답 속도 비교에 유용
로그 패널(Loki)
FastAPI logs (Loki, all levels)
→ 에러·지연 발생 시점 클릭 → 동일 화면에서 즉시 로그 확인
→ 핸들러/상태코드와 로그를 “한 화면에서” 연동해 보는 구조
👉 결론
Service Overview 대시보드가 FastAPI 전체 상태를 보는 레이더라면,
이 A/B & Model Deep Dive 대시보드는 핸들러/alias 단위로 문제를 ‘정밀 추적’하는 확대경입니다.
RPS / Latency(p50/p95) / Error Rate / 로그를
엔드포인트별로 세분화해서 동시에 확인할 수 있고,
모델 핫스왑(A/B) 후 “어느 핸들러가 에러·지연을 일으키는지”
분 단위로 파악 가능한 대시보드입니다.
3️⃣ FastAPI Alert Rule 동작 증명
✔ 3-1. PrometheusRule 실제 반영 상태
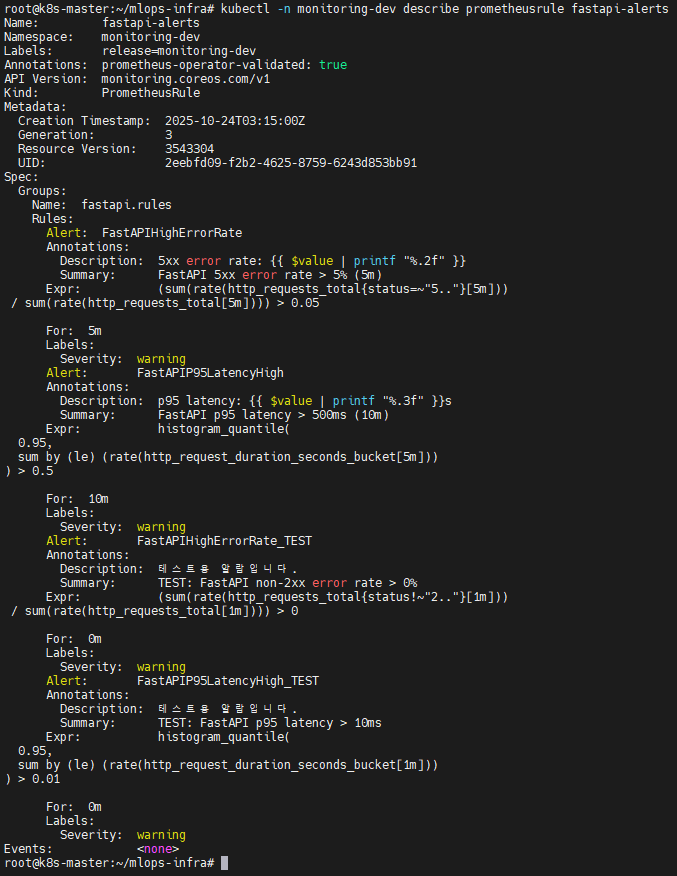
📸 proof-02-fastapi-dev-alert-rule.png
확인 포인트
FastAPIHighErrorRate,FastAPIP95LatencyHigh- 테스트용
FastAPIHighErrorRate_TEST,FastAPIP95LatencyHigh_TEST - 모두 PrometheusOperator를 통해 cluster에 적용 완료
👉 결론: FastAPI 알람 정의가 운영 환경에 정확히 배포되었습니다.
✔ 3-2. Error Rate 증가 시나리오 (404 폭증)
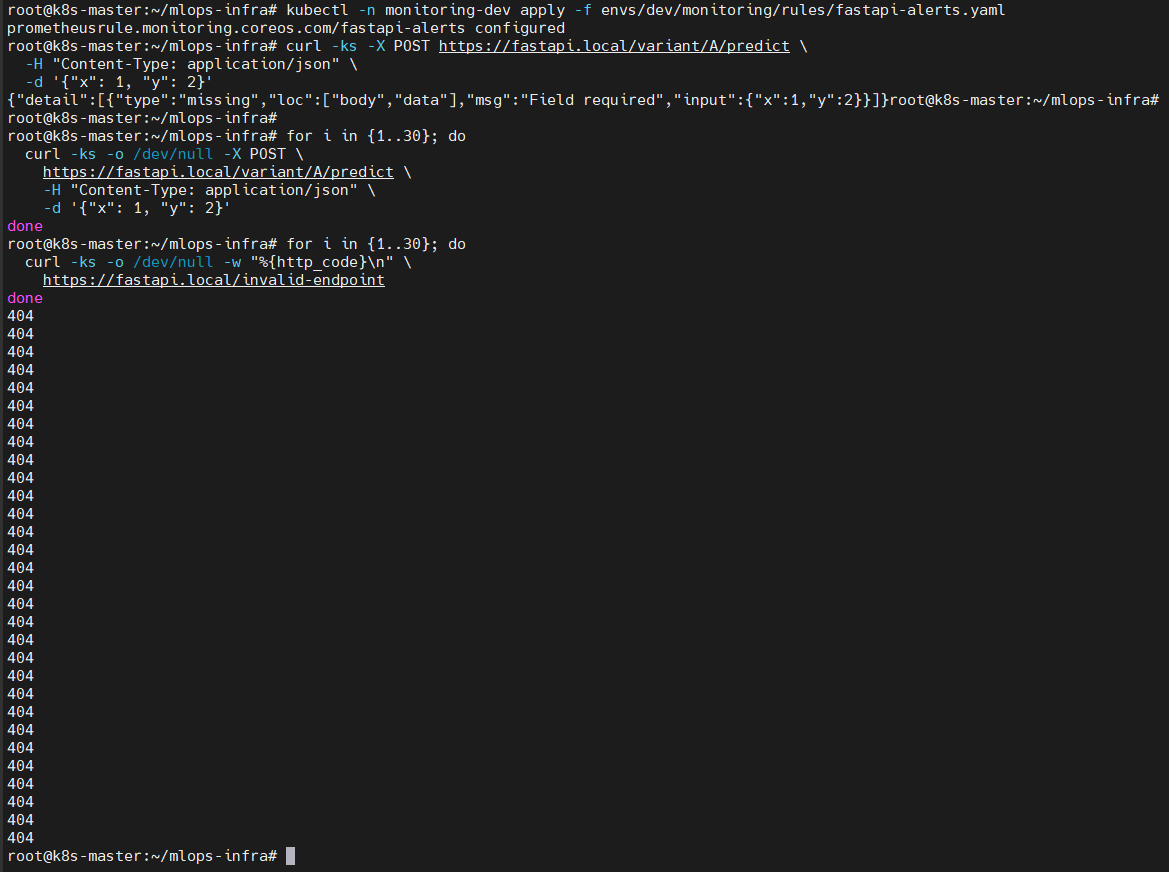
📸 proof-02-fastapi-dev-alert-curl-test.png
실행 내용
- 정상 endpoint로 30회 POST (2xx)
- 존재하지 않는 endpoint로 30회 호출 → 404 연속 발생
- non-2xx 비율 증가 → Alert firing 조건 만족
👉 결론: “FastAPI non-2xx 증가 → Alert 발생” 시나리오가 그대로 재현됩니다.
✔ 3-3. 경량 부하에서도 메트릭 정상 수집
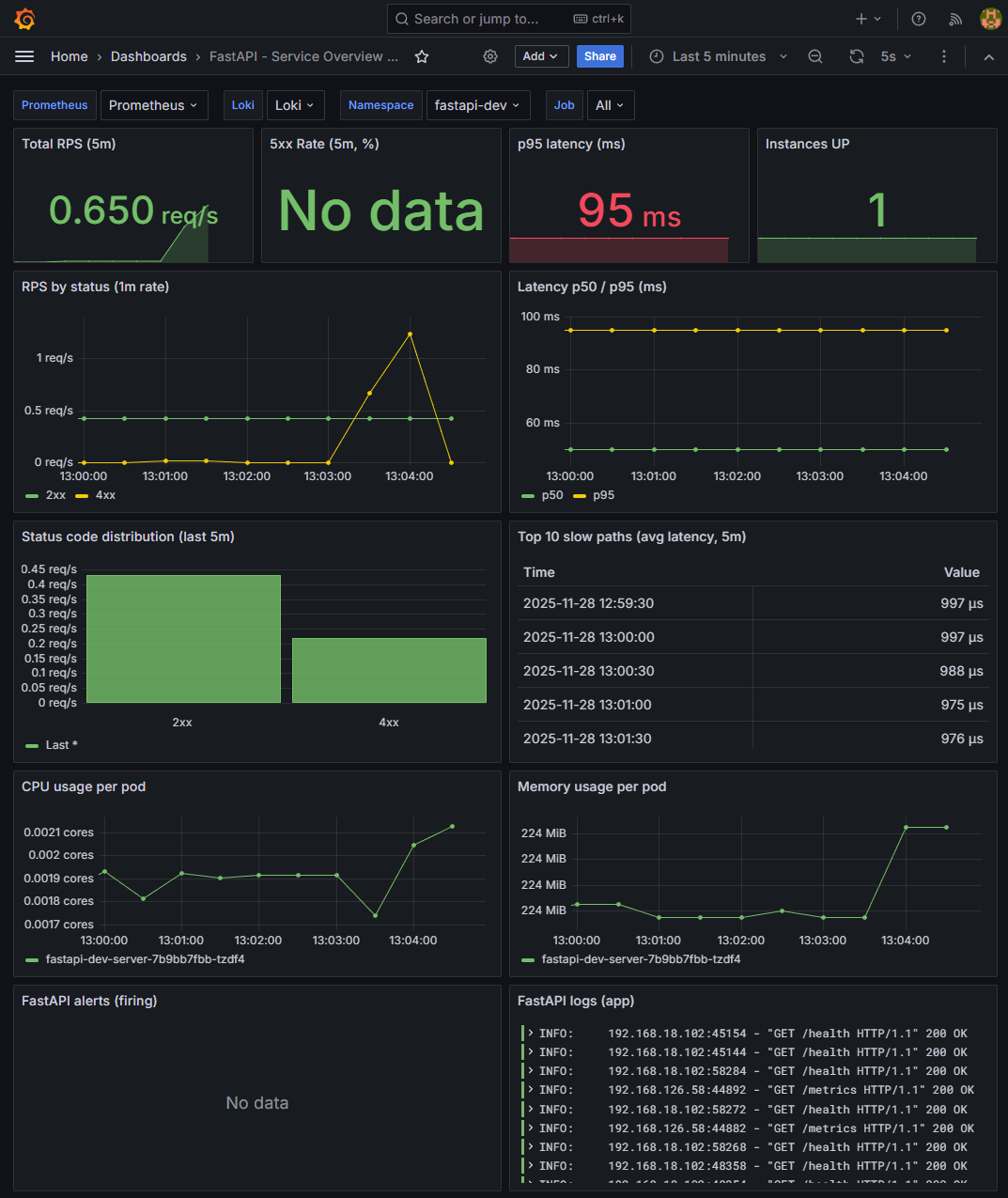
📸 proof-02-fastapi-dev-alert-library-test.png
확인 포인트
- 약 0.65 req/s 의 낮은 트래픽에서도 RPS / Status / CPU / Memory / Slow paths 정상
- 고부하·저부하 상관없이 동일한 대시보드에서 확인 가능
👉 결론: 트래픽 강도에 관계없이 관측 가능성이 항상 유지됩니다.
✔ 3-4. Alertmanager → Slack 알림
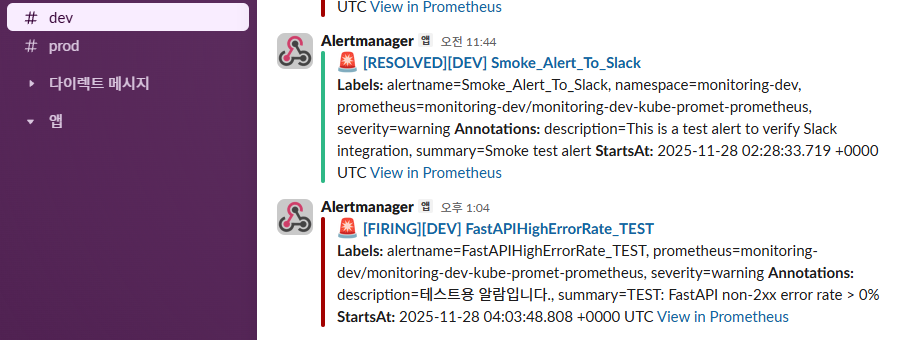
📸 proof-02-fastapi-dev-alert-library-test-slack.png
확인 포인트
- Smoke Alert는 RESOLVED,
FastAPIHighErrorRate_TEST는 FIRING 상태 - Alertmanager → Slack Webhook 파이프라인이 실제 트래픽 기반으로 동작
👉 결론: FastAPI 관련 장애 발생 시 실제 슬랙 알림까지 이어지는 운영 플로우가 검증되었습니다.
C. Data Pipeline (Airflow + S3)
데이터 파이프라인이
Raw 데이터 수집 → 검증 → Feature 생성 → S3 저장 → Raw vs Feature 비교
까지 엔드투엔드로 정확하게 동작했음을 증명합니다.
1️⃣ Raw 데이터 수집(S3) 검증
✔ 1-1. Raw 데이터 버킷 생성
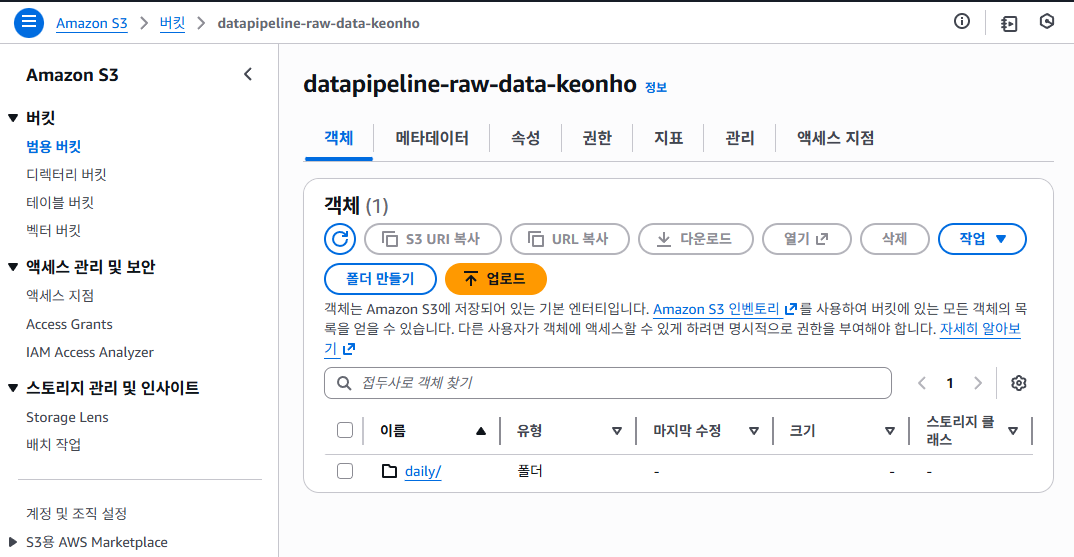
📸 proof-01-s3-daily-raw-data.png
확인 포인트
datapipeline-raw-data-keonho버킷 존재daily/폴더 자동 생성
✔ 1-2. Raw Daily CSV 확인
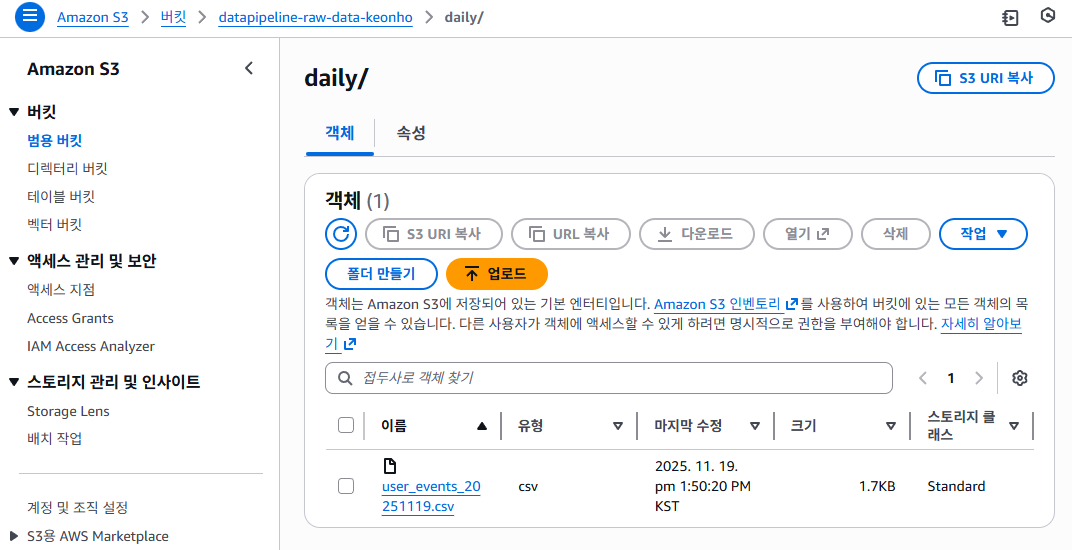
📸 proof-01-s3-daily-raw-data-2.png
확인 포인트
daily/user_events_20251119.csv파일 존재- 크기 1.7KB, CSV 스키마 정상
👉 결론: extract_raw_data 태스크가 Raw 데이터를 S3에 정상 업로드합니다.
2️⃣ Airflow DAG 엔드투엔드 실행
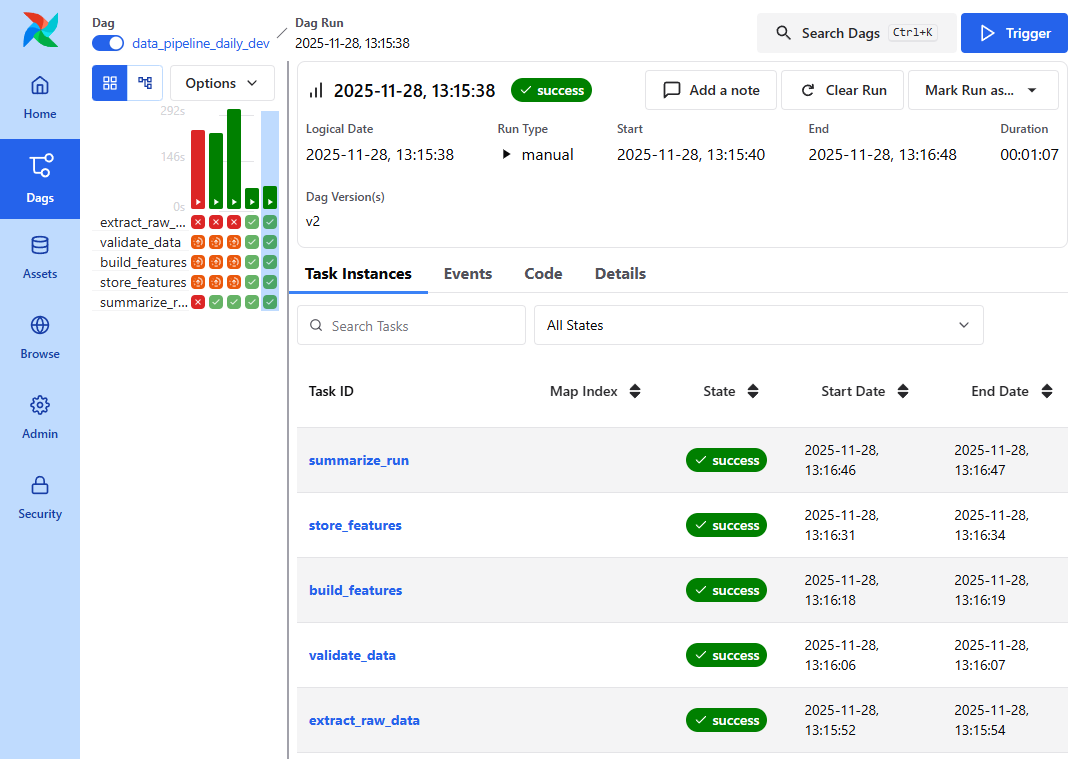
📸 proof-01-airflow-dag.png
확인 포인트
extract_raw,validate_data,build_features,store_features,summarize_run모든 태스크
success전체 실행 시간 약 1분, DAG Version v2
👉 결론: Raw → Feature 전 과정이 중단 없이 한 번에 실행됩니다.
3️⃣ Feature 생성 및 저장 검증
✔ 3-1. features/ 폴더 생성
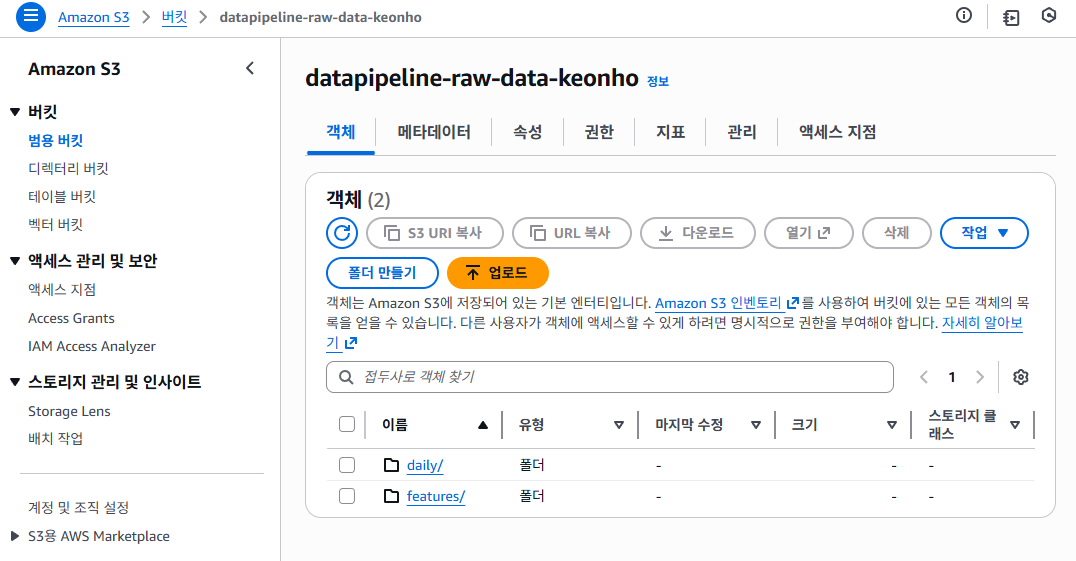
📸 proof-01-s3-features-data.png
확인 포인트
- DAG 실행 후
features/폴더 자동 생성
✔ 3-2. Feature CSV 파일 생성
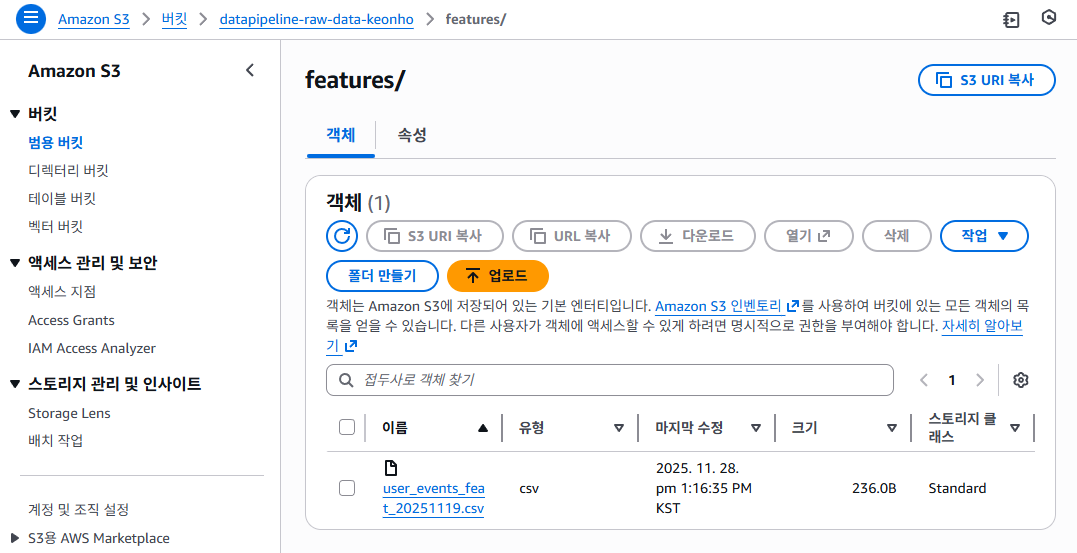
📸 proof-01-s3-features-data-2.png
확인 포인트
features/user_events_feat_20251119.csv존재- 크기 236B → Raw 대비 Feature 컬럼만 남은 형태
👉 결론: store_features 태스크가 Feature Engineering 결과를 S3에 안정적으로 저장합니다.
4️⃣ Raw vs Feature 최종 비교
✔ 4-1. 파일 내용 비교 (엑셀)
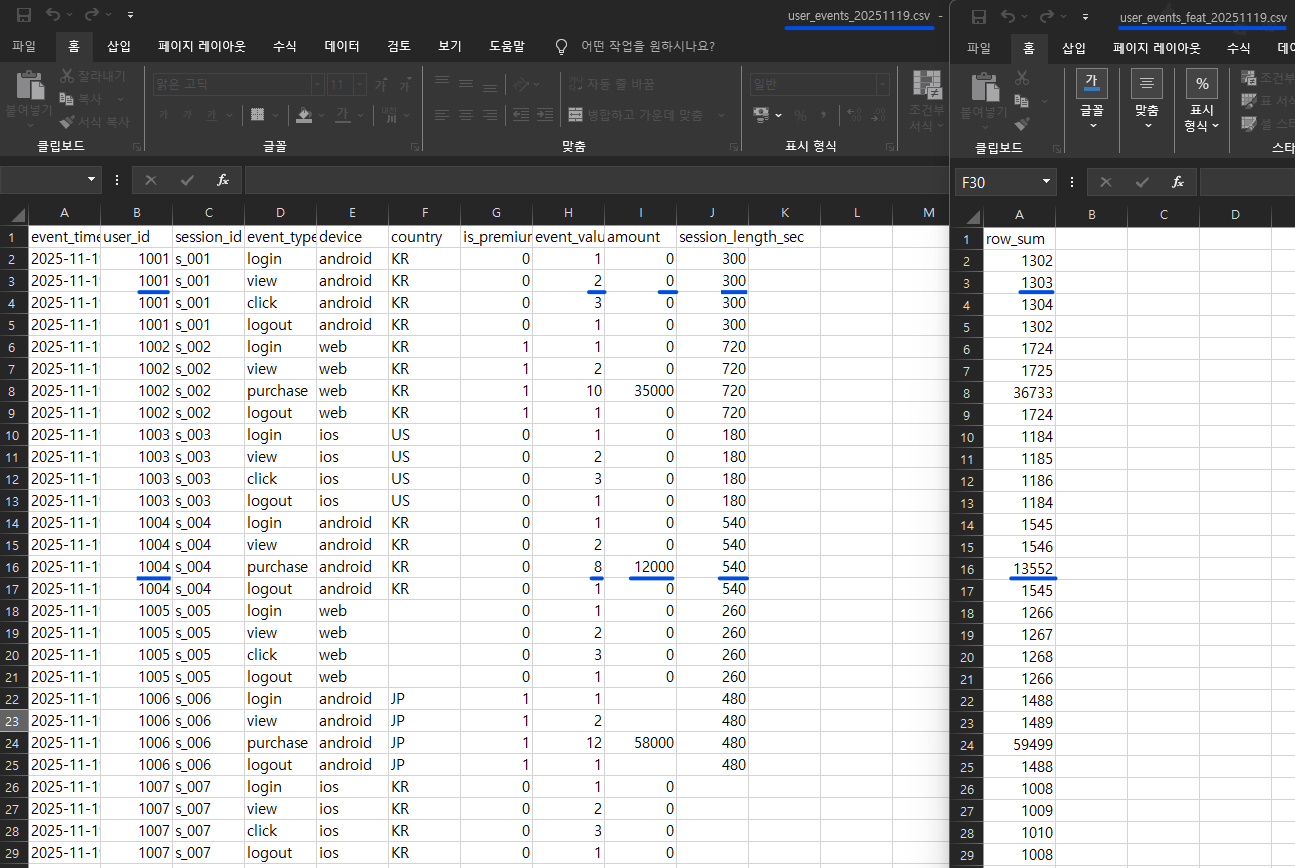
📸 proof-03-compare-file.png
확인 포인트
좌측:
user_events_20251119.csv원본 Raw우측:
user_events_feat_20251119.csvFeature 파일row_sum계산 컬럼 정상 생성13552 같이 값이 크게 나온 row는
amount=12000등고액 결제 이벤트가 합산된 정상 결과
👉 결론: Feature 생성 로직이 설계한대로 숫자형 컬럼을 추출·가공하고 있습니다.
D. Data Pipeline 고도화 (버전 · 스키마 · 메타데이터 · 관측)
앞서 구축한 Data Pipeline v1이 Raw → Feature ETL이 정상 작동함을 증명했다면,
이번 v2에서는 같은 파이프라인이 버전·스키마·메타데이터·관측까지 갖춘 운영형 구조로 동작함을 확인합니다.
1️⃣ S3 버전 디렉터리 구조
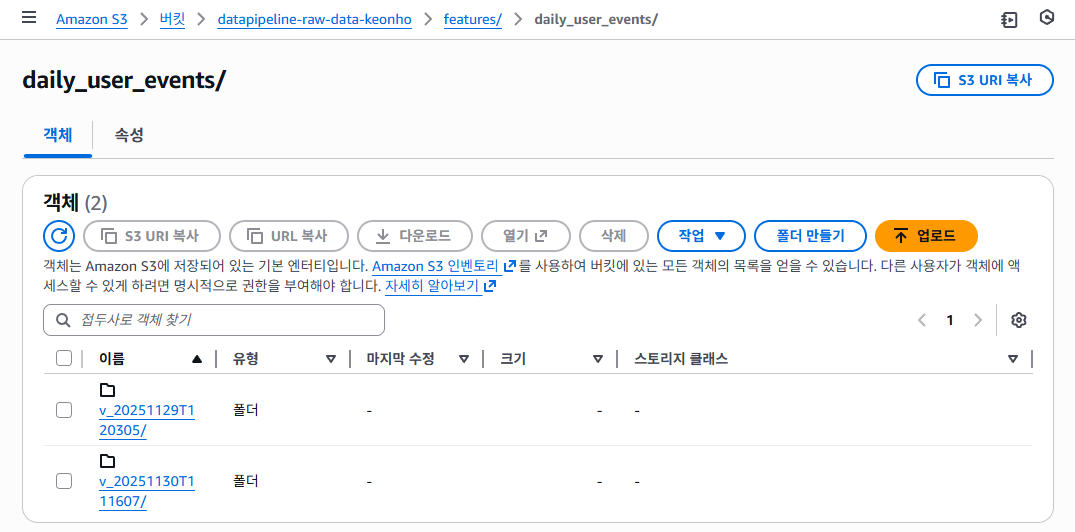
📸 proof-01-s3-daily-user-events-dir-1.png
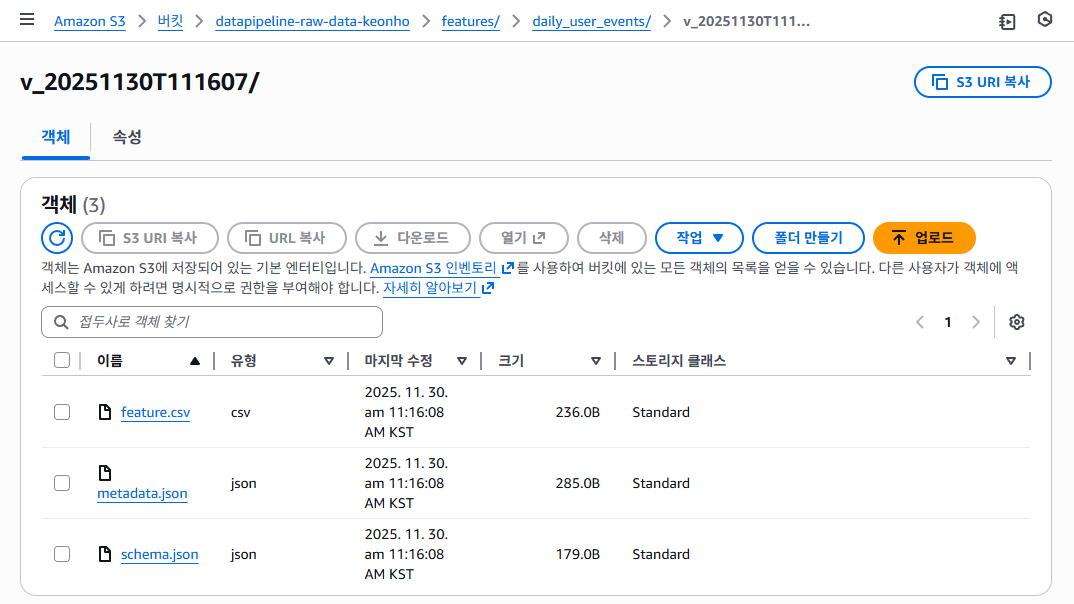
📸 proof-01-s3-daily-user-events-dir-2.png
확인 포인트
features/daily_user_events/하위에v_20251129T111532/,v_20251129T120305/같은 실행 시점 기반 버전 디렉터리 누적- 각 디렉터리 아래에
feature.csv,schema.json,metadata.json3종 세트가 항상 생성
👉 결론: 실행마다 독립된 버전 단위 아티팩트가 기록됩니다.
2️⃣ Airflow DAG v2 엔드투엔드 실행
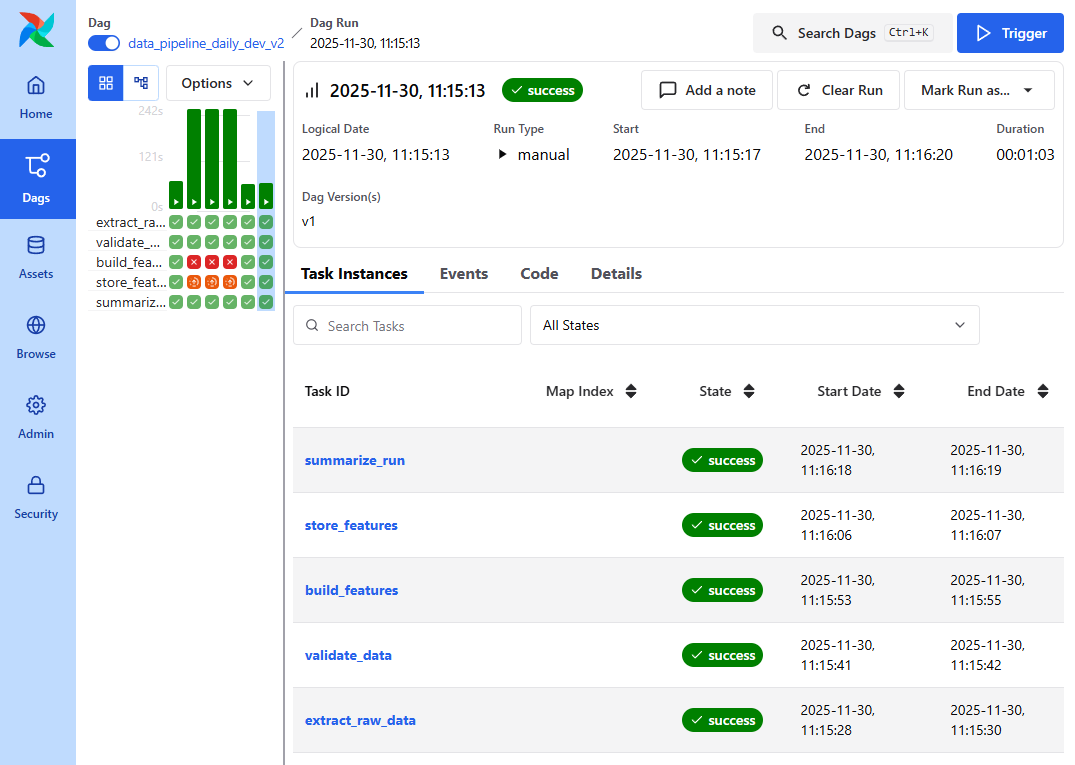
📸 proof-02-airflow-dag-v2.png
확인 포인트
- DAG:
data_pipeline_daily_dev_v2 - 구성: extract_raw → validate_data → build_features → store_features → summarize_run
- 모든 태스크 success
👉 결론: Raw → Feature → 요약까지 끊김 없이 자동 실행됩니다.
3️⃣ Feature 버전 정보 (schema · metadata · 품질 교차 검증)
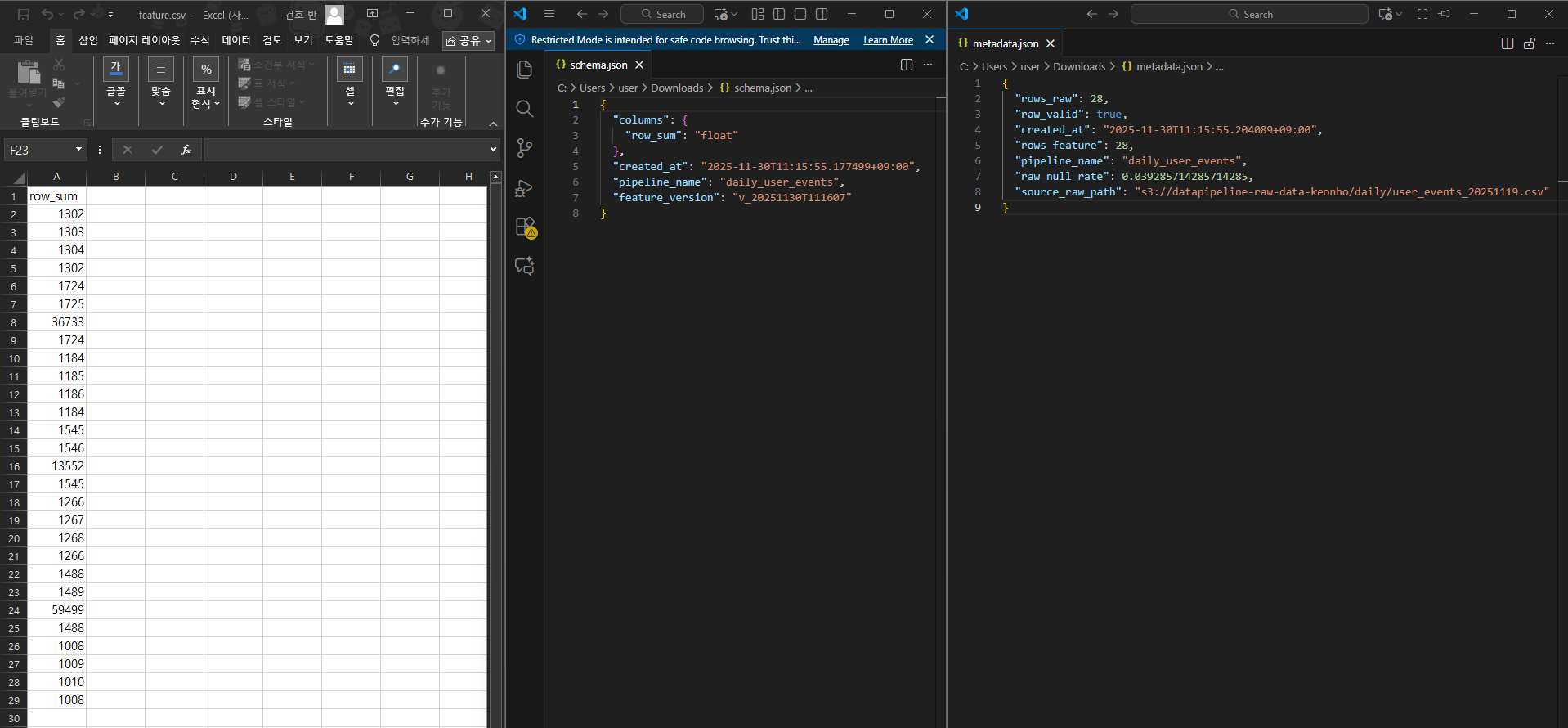
📸 proof-03-feature-schema-metadata.png
확인 포인트
schema.jsonfeature_version이 S3 디렉터리명과 정확히 일치- 생성 시점(KST) 포함
metadata.json- raw/feature row 수, null_rate, raw_valid 상세 기록
- Raw vs Feature
- Airflow 로그(rows/null_rate)와 S3 파일(metadata.json)과 CSV 실데이터가 모두 동일
👉 결론: 스키마/메타데이터/품질 3중 검증으로 안정성을 확보합니다.
4️⃣ Grafana 관측 (Logs + Pipeline Runs)
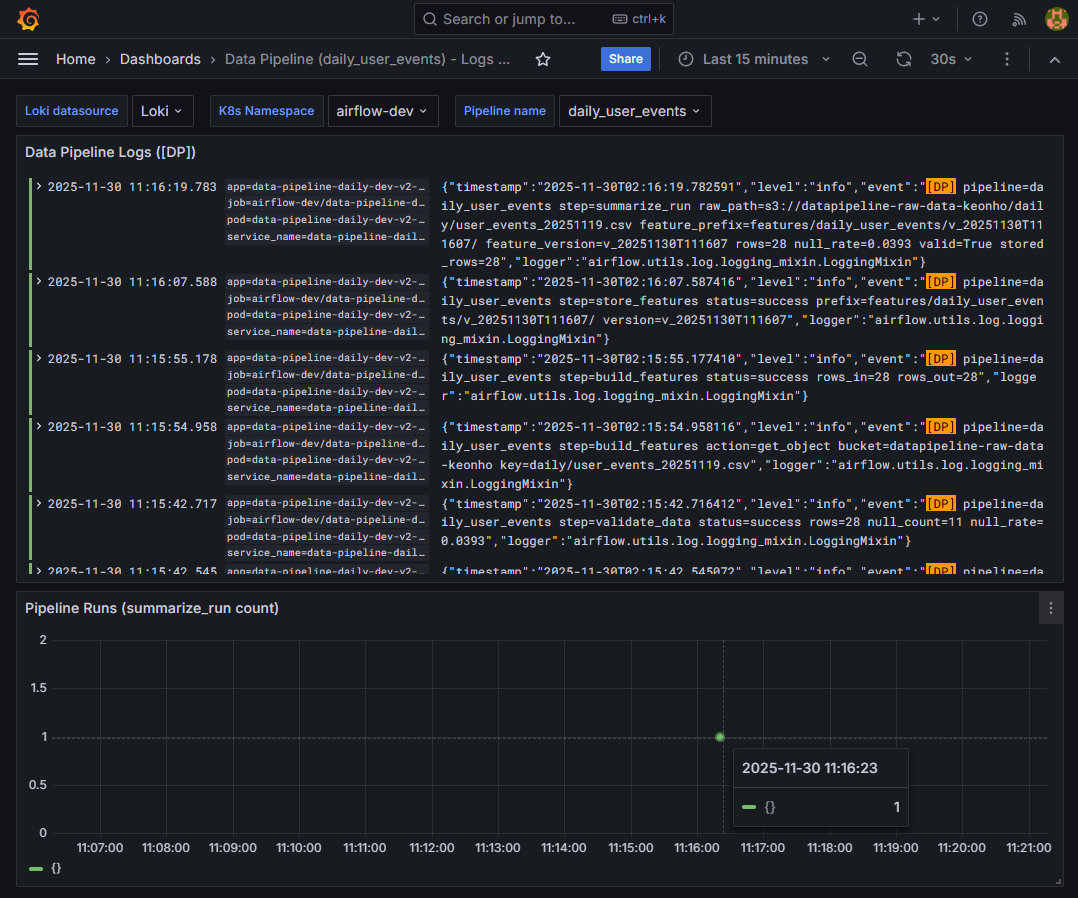
📸 proof-04-grafana-dp-logs-runs.png
확인 포인트
[DP]로그로 단계별 실행 흐름(time-ordered) 확인- summarize_run count 패널로 실행 시간대·빈도 확인
- 버전 정보와 실행 패턴이 한 화면에 표현
👉 결론: 로그·메트릭 기반의 운영형 관측이 완성되었습니다.