에필로그 — “관측·알림·데이터까지 한 번에 이어지는 MLOps 운영 플랫폼”
📌 전체 경로 요약
🎯 전체 회고 요약
| 단계 | 핵심 목표 | 주요 개선점 |
|---|---|---|
| 1 | 모니터링 뼈대 구축 | kube-prometheus-stack dev/prod 완전 분리 |
| 2 | Slack 알람 통합 | Alertmanager configSecret 표준화 + 알람 라우팅 |
| 3 | 메트릭 교차 수집 제거 | KSM/Kubelet 라벨 통일, Prometheus TSDB local-path |
| 4 | 로그 파이프라인 완성 | Loki/Promtail dev/prod 분리 + LogQL Range Query |
| 5 | 실제 운영 이슈 해결 | 라벨/Secret/NFS 권한/NFS unmount 문제 일괄 해결 |
| 6 | FastAPI/Platform 관측 대시보드 | FastAPI 서비스 + Kubernetes/Node 플랫폼 관측 체계 완성 |
| 7 | Data Pipeline 구축 (v1) | S3 Raw → Feature ETL 자동화 (Airflow DAG) |
| 8 | Data Pipeline 고도화 (v2) | 버전·스키마·메타데이터 자동화 + 관측 대시보드 |
| 9 | 검증 | Observability 계층, Grafana 대시보드, Datapipeline |
🔄 핵심 문장:
“Commit → Deploy → Train → Reload → Observe → Alert → Rollback” 전체 흐름이 하나의 루프로 묶였습니다.
🧩 Observability + Data Plane 전체 구조
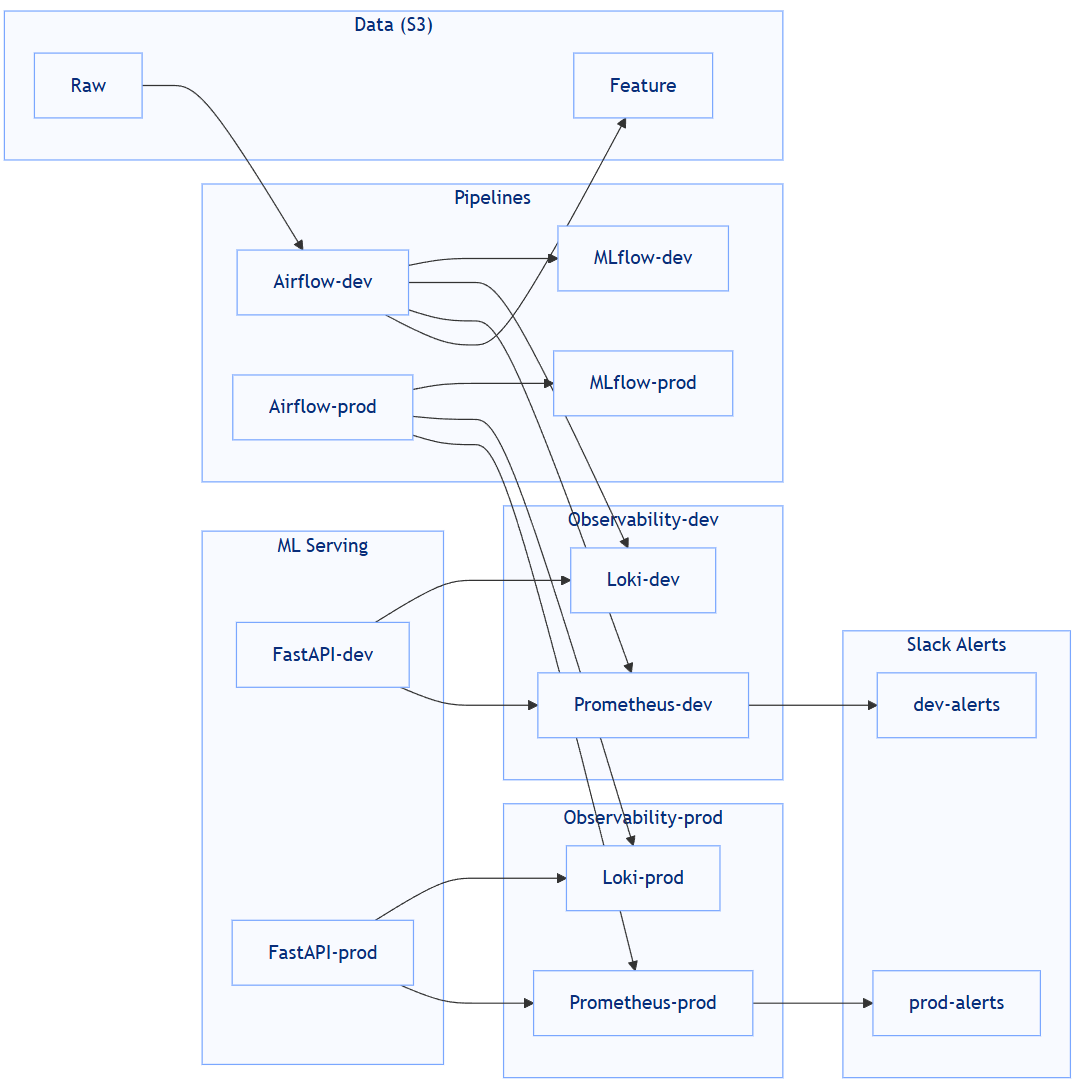
요약하면:
APP 계층: FastAPI / Airflow / MLflow가 모델 학습·등록·서빙을 담당하고,
DATA 계층: S3 Raw/Feature가 데이터 수명주기를 책임지며,
OBS 계층: Prometheus / Alertmanager / Grafana / Loki가
메트릭·알람·로그를 dev/prod 완전히 분리해서 끌어안고 있습니다.
🔁 One Commit → Observability → Data Pipeline Flow
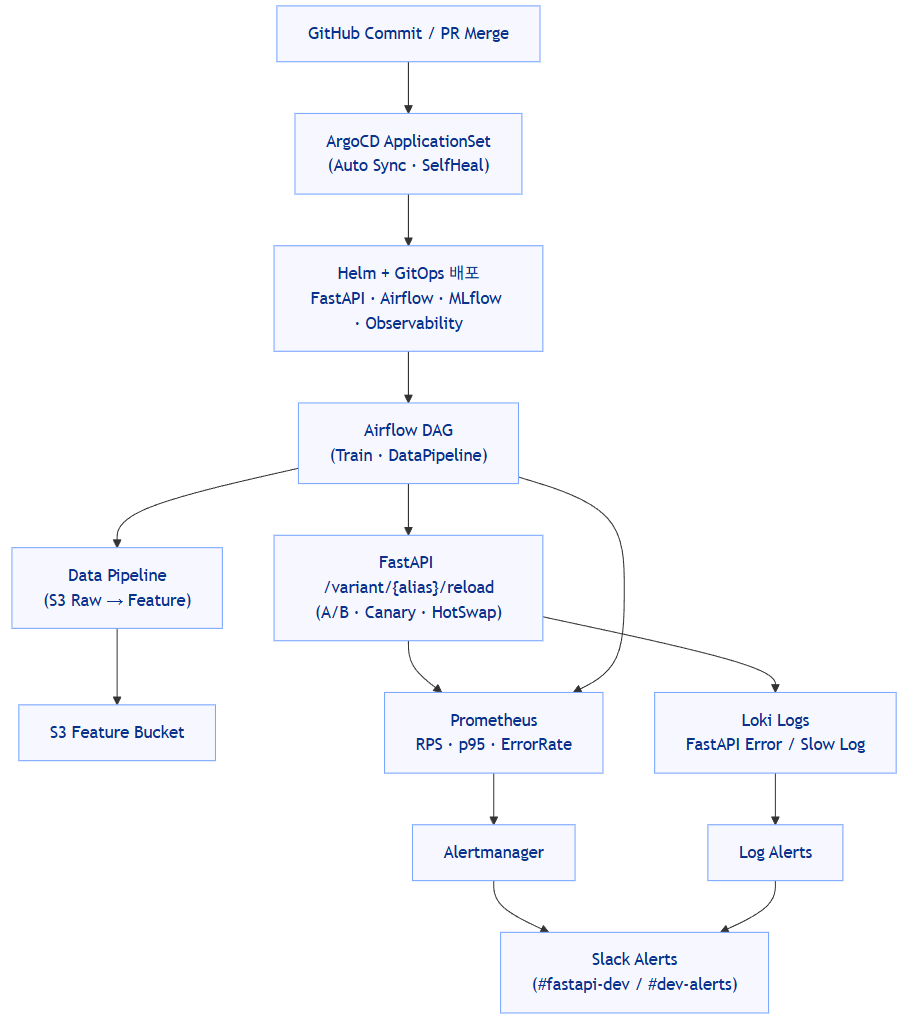
한 줄로 요약하면:
Commit → GitOps 배포 → Airflow 학습/데이터 파이프라인 → FastAPI 핫스왑 → 메트릭·로그·알람 → Slack → (필요 시) 롤백/조치 까지 한 루프 안에서 자연스럽게 돌도록 설계한 시리즈입니다.
🧠 운영 원칙 정리
환경 분리
monitoring-dev / monitoring-prod,loki-dev / loki-prod,fastapi-dev / fastapi-prod→ 관측·로그·서빙 모두 dev/prod 라벨·셀렉터 기준으로 절단
Observability 표준
- 메트릭: Prometheus + kube-prometheus-stack
- 로그: Loki + Promtail, LogQL Range Query 기준
- 알람: Alertmanager → Slack, Watchdog·잡소음 null receiver 필터링
성능·안정성
- Prometheus TSDB:
local-path(고 IOPS) - Grafana / Alertmanager / Loki: NFS(
nfs-observability)로 장기 보관
- Prometheus TSDB:
FastAPI 운영 규칙
/metrics→ Prometheus/predict,/variant/{alias}/predict,/variant/{alias}/reload경로는A/B·Canary·Blue-Green을 모두 수용하는 베이스 라우팅
FastAPI 전용 Dashboard & Alert Library로
지연·에러·인스턴스 다운·로그 스파이크를 즉시 감지
데이터 파이프라인
- S3 Raw → Extract/Validate/Feature/Store → Feature S3 (Airflow DAG 자동화)
- 실행마다
v_타임스탬프폴더 생성 후feature.csv / schema.json / metadata.json저장 - KST 버전 관리 + 실행 품질(Log/Loki)까지 한 번에 추적
GitOps 복원력
- 모든 구성(YAML / Helm values / SealedSecret)은 Git 기준
- 새 클러스터를 깔아도 A·B·C 시리즈 전체를 그대로 재현 가능
✅ 최종 점검 체크리스트
prometheus-{dev,prod}.local에서 서로 다른 namespace만 보이는지(dev에서 prod 메트릭이 섞이지 않는지)
Alertmanager
/api/v2/status에서configSecret=alertmanager-config-{dev,prod}로 연결되어 있는지Loki
/loki/api/v1/query_range로namespace=fastapi-{dev,prod},airflow-{dev,prod}로그가 정상 조회되는지FastAPI 대시보드에서 RPS / p95 / ErrorRate / 로그 패널이
동일 시간대에 같은 패턴을 보여주는지
Data Pipeline DAG(Extract → Validate → Build Features → Store → Summarize)가
Raw S3 → Feature S3까지 에러 없이 한 번에 흐르는지
Slack에 FastAPI / Observability / Data Pipeline 관련 알람이
dev·prod 각 채널로 정확히 분리되어 들어오는지
Data Pipeline v2가 Raw S3 → Feature S3까지 정상 실행되는지 (
v_타임스탬프버전 디렉터리 + 3종 파일 생성 여부)Grafana “Logs & Metrics (Compact)”에서
[DP]로그와 summarize_run이 정상 표시되는지
🏁 회고
관측·알림 인프라의 뼈대와 안정성을 만들고,
FastAPI 중심 관측·알람 레이어를 얹었으며,
데이터 파이프라인 레이어까지 완성했습니다.
구성한 로컬 클러스터는
“모델이 학습되고, 배포되고, 문제가 생기면 바로 감지되고,
데이터부터 로그·메트릭·알람까지 한 번에 추적 가능한 운영형 ML Platform” 이 되어 있습니다.
🙌 프로젝트 GitHub 저장소
- GitHub 코드: [GitOps] mlops-platform
- DAG 코드: [DAG] airflow-dags