이 글에서 다루는 것
Triton Inference Server를 CPU-only GitOps 구조로 배포하고, ONNX 모델 1개의 load/infer 검증 및 Prometheus/Grafana 관측까지 서빙 플랫폼 뼈대를 구축한 과정
선수지식
이 단계에서 해결하려는 문제
실무에서 서빙 계층은 곧바로 트래픽과 SLA를 맞는 최전선이다. 모델이 아무리 좋아도 서빙이 불안정하면 운영 시 바로 무너진다. 이번에는 Triton 첫 구축으로 GPU/파이프라인 연동을 일부러 빼고, Triton 자체를 GitOps로 안정적으로 띄우고, 모델 load → infer → metrics 관측까지 서빙 플랫폼 뼈대 구축을 진행했다.
🎯 핵심 요약
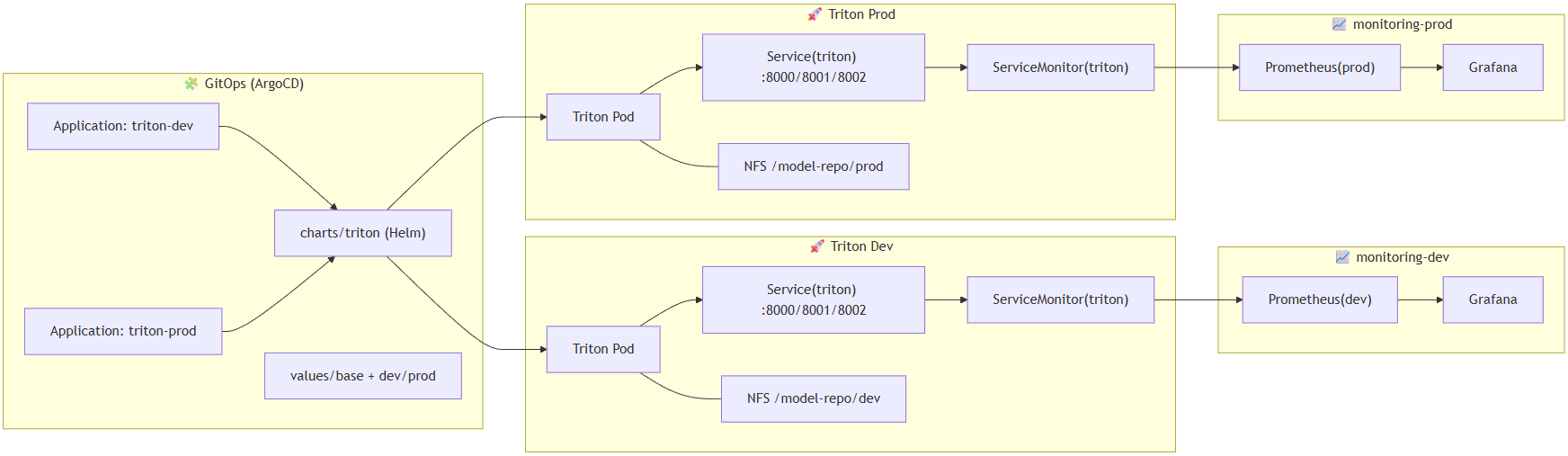
- dev/prod 네임스페이스 분리:
triton-dev,triton-prod - Triton 모델 제어 모드:
--model-control-mode=explicit(필요 시에만 load/unload) - Model Repository: NFS(RWX) 기반 PVC로
/models마운트 - 모델 검증: ONNX 1개
simple_model로load → infer성공 - 관측: Triton
/metrics를 Prometheus 포맷으로 자체 노출, ServiceMonitor로 자동 스크랩, Grafana 패널로 증명 - GPU 확장 포인트: values에
gpu.enabled분기 설계 (현재 false → CPU 사용)
1️⃣ 전체 구조 요약
2️⃣ 코드 트리
charts/triton/
├── Chart.yaml
├── templates/
│ ├── deployment.yaml
│ ├── service.yaml
│ └── serviceMonitor.yaml
└── values/
├── base.yaml
├── dev.yaml
└── prod.yaml
3️⃣ 설계 포인트
(1) 서빙 계층 분리
- FastAPI는 API Gateway/비즈니스 라우팅 계층
- Triton은 Inference 전용 서빙 계층
- 운영/스케일링/리소스 성격이 다르기 때문에 분리했다.
(2) explicit 모드 선택
- 자동 로딩이 아니라 필요할 때만 모델 load
- 운영에서 모델 배포/교체는 항상 위험 구간이라 통제 가능한 방식(Explicit)으로 진행했다.
(3) GitOps에서 dev/prod 관측 라벨 정합성
- Prometheus는 연결이 아니라 라벨로 발견한다 (= exporter 연결이 아닌 label 탐색)
- dev Prometheus는
release=monitoring-dev라벨의 ServiceMonitor만 스크랩 - prod는
release=monitoring-prod만 스크랩 - 서비스/서비스모니터에 release 라벨이 핵심이었다.
4️⃣ Helm values 핵심
values/base.yaml
- 이미지:
nvcr.io/nvidia/tritonserver:24.08-py3 - 포트: HTTP 8000 / gRPC 8001 / Metrics 8002
- 리소스: CPU-only
- NFS PVC를
/models로 마운트 - GPU 확장 포인트는 flag만 두고 이번에는 false로 CPU 사용
values/dev.yaml / values/prod.yaml
global.env를dev/prod로 분리monitoring.releaseLabel을 각 환경별로 지정 (dev →monitoring-dev, prod →monitoring-prod)
5️⃣ Kubernetes 리소스 핵심 (Service / ServiceMonitor)
5-1) Service.yaml 핵심
- Service에
app,env,release라벨을 부여 - ServiceMonitor가 이 라벨을 기준으로 대상 발견
- Service가 metrics 포트를 노출해야 ServiceMonitor가 붙는다.
5-2) ServiceMonitor.yaml 핵심
- Prometheus의
serviceMonitorSelector.matchLabels.release와 맞춰야 함 namespaceSelector.matchNames: [ Release.Namespace ]로 dev/prometheus가 dev namespace 안의 서비스만 긁게 고정
6️⃣ Model Repository (NFS, RWX)
NFS 최종 구조
/mnt/nfs_share/mlops/triton/model-repo/
├── dev/
│ └── simple_model/
│ ├── config.pbtxt
│ └── 1/
│ └── model.onnx
└── prod/
└── simple_model/
├── config.pbtxt
└── 1/
└── model.onnx
- PV/PVC는 dev/prod 각각 다른 path로 분리
- PVC는 namespace 안에서 동일 이름(
triton-model-repo-pvc)을 사용해도 되게 설계 (namespace가 격리)
7️⃣ 모델 준비 (ONNX)
STEP 1) ONNX export (k8s-master)
- 처음엔
onnxscript가 없어 export 실패 → 설치 후 해결 - opset downgrade 경고/실패가 있었지만 결과물 생성은 됨
- 최종적으로 opset 18로 고정하는 편이 안전했음
STEP 2) 파일 전달
- 랩 편의상: k8s-master → Windows(MobaXterm) → NFS 서버 업로드
- 대안: NFS mount / initContainer로 자동 동기화 가능
STEP 3) config.pbtxt에서 shape mismatch 이슈
- 실제 ONNX input shape:
[1,4] - config.pbtxt에
[4]로 적으면 load 실패 → Triton이 아주 엄격하게 검사
8️⃣ 모델 로드/상태/추론 검증
8-1) Load + Status + Ready 확인
POST /v2/repository/models/simple_model/loadGET /v2/models/simple_modelGET /v2/health/ready
성공 시 status에서 inputs/outputs shape 확인 가능, ready 200 OK
8-2) Infer 요청
POST /v2/models/simple_model/infer- JSON 입력 shape
[1,4]로 요청 → 정상 응답
이 시점에서 서빙 자체는 완성이다.
9️⃣ /metrics 확인 (핵심 증명)
처음 /metrics에는 CPU 관련 최소 지표만 보일 수 있다.
infer를 1~2번이라도 수행하면 아래가 등장한다:
nv_inference_request_successnv_inference_request_duration_usnv_inference_queue_duration_usnv_inference_count
실제로 infer를 쐈고, Triton이 그 사실을 메트릭으로 남긴다.
🔟 Grafana 대시보드 (JSON Import)
Grafana에서 Dashboard → Import → JSON 붙여넣기
- 변수: datasource / namespace / model
- 핵심 5패널: RPS / Avg Latency / Avg Queue / CPU / Total Count
🧩 팁
- 초기엔 inference 메트릭이 안 보이는 게 정상이다 (infer를 한 번이라도 쏴야 생김).
ServiceMonitorSelector는 결국 release 라벨 매칭이다. Prometheus 쪽 selector와 ServiceMonitor labels가 1:1로 맞아야 한다.- Triton은 config.pbtxt의 shape/dims를 아주 엄격하게 본다. ONNX input shape와 config dims 불일치는 가장 흔한 함정이다.
설계 판단 (Why This Way?)
explicit 모드를 선택하여 불완전한 파일 업로드 중 자동 로딩 실패를 방지하고 배포 타이밍을 DAG가 완전히 통제하도록 했습니다. NFS(RWX)는 예측 가능한 로딩 시간과 다중 Pod 동시 읽기를 보장하며, CPU-only로 시작하여 GPU 호환성 문제와 서빙 플랫폼 구축을 분리해 디버깅 범위를 좁혔습니다.
다음에 읽을 글
→ Triton 서빙 플랫폼 - MLflow → Triton 자동 배포 파이프라인 — 모델 레지스트리 연동 자동화