이 글에서 다루는 것
기존 v1 데이터 파이프라인에 버전 디렉터리 구조, schema.json, metadata.json, KST 타임라인을 얹어 ML Feature Store에 가까운 v2 파이프라인으로 고도화한 과정
선수지식
이 단계에서 해결하려는 문제
이전 단계에서 S3 Raw에서 Feature CSV까지 동작하는 엔드투엔드 데이터 파이프라인(v1)을 만들었다. 하지만 실무 ML 플랫폼 입장에서는 “그때 그 실행에서 어떤 데이터를, 어떤 품질로, 어느 버전에 저장했는지"가 시간/버전/스키마/메타데이터까지 한 번에 남아야 한다. 이번 단계에서는 기존 v1 파이프라인을 버리지 않고, 그 위에 버전 디렉터리 구조 + schema.json + metadata.json + KST 타임라인을 얹어 실제 ML Feature Store에 더 가까운 v2 파이프라인으로 고도화했다.
🎯 핵심 요약 (v1 → v2 변화 한눈에 보기)
- 저장 방식
- v1:
features_20251119.csv같은 단일 CSV 파일로 저장 (덮어쓰기 구조) - v2: 실행마다
.../features/daily_user_events/v_YYYYMMDDTHHMMSS/아래에feature.csv+schema.json+metadata.json3종 세트로 버전 디렉터리 생성
- v1:
- 시간/타임존
- v1:
datetime.utcnow().isoformat()기반 (명시적 타임존 관리 X) - v2:
datetime.now(KST)기반으로 항상 한국 시간(KST) 기준 기록
- v1:
- 메타데이터
- v1: 데이터 품질/라인리지 정보는 로그에만 존재
- v2:
schema.json(컬럼/타입, pipeline_name, feature_version, created_at)과metadata.json(source_raw_path, rows_raw, rows_feature, null_rate, valid)을 파일로 저장. 다른 시스템에서 읽기만 해도 해당 실행의 의미를 바로 이해할 수 있다.
- 코드 구조
- DAG:
dag_data_pipeline_daily.py→dag_data_pipeline_daily_v2.py추가 (기존도 유지) - 로직:
ml_code/data_pipeline.py→ml_code/data_pipeline_v2.py로 확장
- DAG:
1️⃣ 전체 구조 (v2 기준)
기본 플로우는 v1과 동일하지만, Feature 저장 이후의 S3 구조와 메타데이터가 완전히 달라진 상태다.
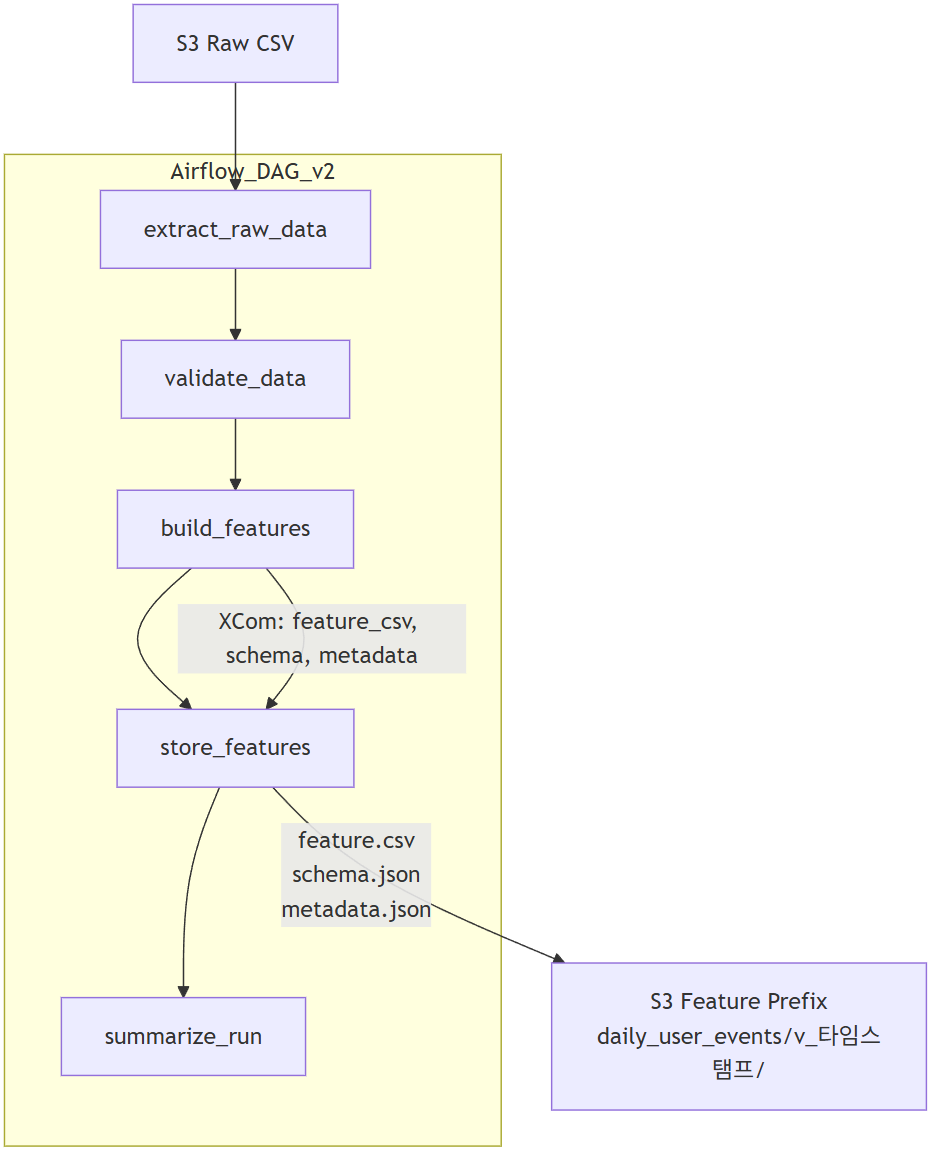
2️⃣ 구성 요소 (v1 대비 추가/변경된 파일)
✅ DAG 레벨
- 기존:
dag_data_pipeline_daily.py→ml_code.data_pipeline사용 - 신규:
dag_data_pipeline_daily_v2.py→ml_code.data_pipeline_v2사용
두 DAG가 같이 존재하므로 v1 구조 테스트용(data_pipeline_daily_dev)과 v2 구조(data_pipeline_daily_dev_v2)를 병행 운영/비교 가능하게 설계했다.
✅ Python 로직 레벨
airflow-dags-dev/
├── dags/
│ ├── dag_data_pipeline_daily.py # v1
│ ├── dag_data_pipeline_daily_v2.py # v2
│ └── ml_code/
│ ├── data_pipeline.py # v1 로직
│ └── data_pipeline_v2.py # v2 로직
data_pipeline.py: CSV 하나 만들어 S3에 저장하는 단순한 ETL 파이프라인data_pipeline_v2.py: 같은 ETL 흐름 위에 버전 관리 + schema.json + metadata.json + KST 기반 시간 관리를 얹은 파이프라인
3️⃣ v1 → v2: DAG 레벨에서 바뀐 점
v1: dag_data_pipeline_daily.py
from ml_code.data_pipeline import (
extract_raw_data, validate_data, build_features,
store_features, summarize_run,
)
def _get_pipeline_config():
raw_path = Variable.get("dp_raw_path", default_var="s3://...")
feature_path = Variable.get("dp_feature_path",
default_var="s3://datapipeline-raw-data-keonho/features/user_events_feat_20251119.csv")
# ... (이하 생략)
feature_path는 최종 파일 경로로 실행할 때마다 같은 파일 덮어쓰기
v2: dag_data_pipeline_daily_v2.py
from ml_code.data_pipeline_v2 import (
extract_raw_data, validate_data, build_features,
store_features, summarize_run,
)
def _get_pipeline_config():
raw_path = Variable.get("dp_raw_path", default_var="s3://...")
feature_path = Variable.get("dp_feature_path",
default_var="s3://datapipeline-raw-data-keonho/features/daily_user_events/")
# ... (이하 생략)
feature_path의 의미를 “디렉터리 프리픽스"로 변경- 실제 저장 시에는 내부에서 버전 디렉터리를 생성한다:
s3://datapipeline-raw-data-keonho/features/daily_user_events/
└── v_20251129T111532/
├── feature.csv
├── schema.json
└── metadata.json
DAG 입장에서는 변한 게 거의 없고, feature_path를 파일에서 디렉터리 프리픽스로 바꿔서 v2 로직에 넘기는 정도만 달라졌다.
4️⃣ Extract & Validate 단계 (v1과 거의 동일)
✔ extract_raw_data
- S3
head_object로 RAW 파일 존재 확인 - 성공 시
dp_raw_pathXCom 저장
def extract_raw_data(raw_path: str, pipeline_name: str, ti):
s3 = _get_s3_client()
bucket, key = _parse_s3_uri(raw_path)
s3.head_object(Bucket=bucket, Key=key)
ti.xcom_push(key="dp_raw_path", value=raw_path)
✔ validate_data
- CSV 전체 read → row 수 / null_count / null_rate 계산
rows == 0이거나null_rate > 0.5이면 invaliddp_rows,dp_null_rate,dp_validXCom 푸시
v1에서도 존재하던 단계이고, v2에서는 로그와 구현 스타일만 조금 정리된 정도다.
5️⃣ v2의 핵심 1 – build_features에서 스키마/메타데이터까지 생성
v1: Feature CSV만 만들고 끝
feature_header = ["row_sum"]
buf = io.StringIO()
writer = csv.writer(buf)
writer.writerow(feature_header)
writer.writerows(feature_rows)
feature_csv = buf.getvalue()
ti.xcom_push(key="dp_feature_csv", value=feature_csv)
# ... (이하 생략)
v2: Feature + schema.json + metadata.json 설계
from datetime import datetime, timezone, timedelta
KST = timezone(timedelta(hours=9))
def build_features(raw_path, feature_path, pipeline_name, ti):
# row_sum feature_rows 계산 부분은 v1과 동일
schema = {
"feature_version": None, # store_features에서 채움
"columns": {"row_sum": "float"},
"created_at": datetime.now(KST).isoformat(),
"pipeline_name": pipeline_name,
}
metadata = {
"source_raw_path": raw_path,
"rows_raw": ti.xcom_pull(key="dp_rows", task_ids="validate_data"),
"rows_feature": len(feature_rows),
"raw_null_rate": ti.xcom_pull(key="dp_null_rate", task_ids="validate_data"),
# ... (이하 생략)
}
ti.xcom_push(key="dp_schema_dict", value=schema)
ti.xcom_push(key="dp_metadata_dict", value=metadata)
핵심 포인트:
- KST 기준 타임라인:
datetime.now(KST).isoformat()– 블로그/운영에서 보는 시간은 항상 한국 시간 - schema.json 설계: 어떤 컬럼이 어떤 타입인지, 언제 생성됐는지, 어느 파이프라인인지. 다른 시스템(Feature Store, Data Catalog 등)에서 읽을 때 즉시 해석 가능
- metadata.json 설계: RAW → Feature 변환 시 row 수, null_rate, 유효성 여부, RAW 파일 경로. 데이터 품질/계보(lineage)를 파일로 남기는 구조
build_features는 단순 전처리 함수가 아니라 Feature + 스키마 + 메타데이터 패키지를 한 번에 만들어내는 단계로 고도화되었다.
6️⃣ v2의 핵심 2 – store_features에서 버전 디렉터리 + 3종 세트 저장
v1: 단일 CSV 파일 저장
bucket, key = _parse_s3_uri(feature_path)
s3.put_object(Bucket=bucket, Key=key,
Body=feature_csv.encode("utf-8"), ContentType="text/csv")
매 실행마다 같은 key에 덮어쓰기. 버전/실행 이력은 별도 관리 없으면 잃어버린다.
v2: 실행 시간 기반 버전 디렉터리 생성 (KST 기준)
def store_features(feature_path, pipeline_name, ti):
# XCom에서 feature_csv, schema, metadata 수신
exec_date = getattr(ti, "execution_date", None)
if exec_date is None:
exec_date = datetime.now(KST)
else:
exec_date = exec_date.astimezone(KST)
run_ts = exec_date.strftime("%Y%m%dT%H%M%S")
version_id = f"v_{run_ts}"
base_prefix = f"{prefix}{version_id}/"
# feature.csv 저장
s3.put_object(Bucket=bucket, Key=f"{base_prefix}feature.csv", ...)
# schema.json 저장
schema["feature_version"] = version_id
s3.put_object(Bucket=bucket, Key=f"{base_prefix}schema.json", ...)
# metadata.json 저장
s3.put_object(Bucket=bucket, Key=f"{base_prefix}metadata.json", ...)
# ... (이하 생략)
S3 구조 예시:
s3://datapipeline-raw-data-keonho/features/daily_user_events/
├── v_20251129T111532/
│ ├── feature.csv
│ ├── schema.json
│ └── metadata.json
├── v_20251129T141030/
│ ├── feature.csv
│ ├── schema.json
│ └── metadata.json
└── ...
이 구조 덕분에 실행 시점별 버전 비교, 특정 날/실행 버전 재현, 스키마/품질 변화를 시간축에 따라 추적하는 것이 파일 구조만 봐도 가능해졌다.
7️⃣ v2의 핵심 3 – summarize_run: 버전까지 포함한 실행 요약
logger.info(
"[DP] pipeline=%s step=summarize_run raw_path=%s feature_prefix=%s "
"feature_version=%s rows=%s null_rate=%.4f valid=%s stored_rows=%s",
pipeline_name, raw_path, feature_prefix, feature_version,
rows, null_rate, valid, stored_rows,
)
로그 한 줄만 봐도 어떤 RAW에서 어떤 버전 디렉터리로 몇 건을 저장했는지, 데이터 품질은 어땠는지 정확하게 재구성 가능하다.
Loki / Grafana에서 이 로그를 쿼리하면 버전별 파이프라인 성공/실패/품질 상태를 한 번에 모니터링할 수 있는 기반이 된다.
8️⃣ 실전 Troubleshooting/운영 관점에서 얻은 것
- S3 Explorer / AWS 콘솔만 봐도: 오늘 새벽 파이프라인이 돌았는지, 어떤 버전이 마지막으로 성공했는지, schema/metadata에서 데이터 품질이 어땠는지 바로 확인 가능
- Loki 로그 쿼리로:
feature_version="v_..."조건으로 특정 실행만 필터링, null_rate가 비정상적으로 높았던 실행만 모아서 확인 - MLflow, Feature Store, Data Catalog를 붙일 때: 코드를 다시 파고들지 않고 schema.json / metadata.json을 기준으로 메타데이터 인입이 가능
9️⃣ Data Pipeline 전용 Grafana 대시보드
v2 파이프라인은 S3 구조와 schema/metadata만 고도화된 게 아니라, Loki 로그를 기준으로 파이프라인 관측 전용 대시보드까지 적용했다.
✔ 대시보드 개요
- 제목:
Data Pipeline (daily_user_events) - Logs & Metrics (Compact) - 태그:
mlops,data-pipeline,loki - 템플릿 변수:
datasource(Loki),namespace(K8s 네임스페이스),pipeline(파이프라인명)
✔ 패널 구성
- Data Pipeline Logs ([DP]) – Logs 패널
- 쿼리:
{namespace="$namespace"} |= "[DP]" |= "pipeline=$pipeline" - Airflow 로그 중
[DP]태그가 붙은 로그만 필터링해서 각 단계가 어떻게 흘렀는지 시간순으로 확인
- 쿼리:
- Pipeline Runs (summarize_run count) – TimeSeries 패널
- 쿼리:
sum by (pipeline) (count_over_time({namespace="$namespace"} |= "[DP]" |= "step=summarize_run" [$__interval])) - 파이프라인이 언제, 얼마나 자주 실행됐는지를 시계열로 확인
- 쿼리:
✔ 운영에서의 사용 포인트
- 새 Raw 데이터가 들어왔을 때 Logs 패널에서
[DP]흐름을 따라가며 어디에서 실패했는지 바로 파악 - 특정 시간대에 파이프라인이 안 돌았다고 의심될 때 TimeSeries 패널에서
summarize_run카운트로 빠르게 확인 - 주기적인 스케줄 상태를
Last 24 hours / Last 7 days로 바꿔보면서 패턴이 깨진 구간 관찰
각 실행의 자세한 단계 로그(Logs) + 실행 빈도/패턴(TimeSeries) 두 가지 관점으로 Data Pipeline을 모니터링하는 최소 대시보드다.
설계 판단 (Why This Way?)
v1을 제거하지 않고 v2를 병행하여 전환 중 운영 중단 없이 출력 비교 검증 후 점진적 마이그레이션을 가능하게 했습니다. schema.json(변경 빈도 낮음)과 metadata.json(실행별 품질/계보)을 분리하고, 시간 기반 버전 ID로 S3에서의 정렬·필터링과 실행 시점 즉시 파악을 지원합니다.
다음에 읽을 글
→ Triton 서빙 플랫폼 - Triton 구축 — ONNX 모델 기반 Triton 배포