이 글에서 다루는 것
S3 Raw 데이터를 Airflow DAG로 추출/검증/가공/저장하는 엔드투엔드 데이터 파이프라인을 구축하여 ML 학습 자동화의 데이터 레이어를 확보한 과정
선수지식
이 단계에서 해결하려는 문제
모델의 성능은 결국 데이터 품질에서 결정된다. 그런데 데이터를 어떻게 추출하고, 검증하고, 가공하고, 저장하는지까지 자동화하지 않으면 MLOps는 완성되지 않는다. 이번 단계에서는 Raw S3에서 전처리, Feature 생성, 저장까지 이어지는 엔드투엔드 데이터 파이프라인을 직접 구축해 이후 MLflow 학습 자동화와 바로 연결될 데이터 레이어를 다졌다.
🎯 핵심 요약
- Raw 데이터를 S3에서 가져오고
- Airflow DAG에서 단계별 처리 흐름을 관리하며
- Python 전처리 코드에서 Feature 생성
- 최종 Feature를 Feature Bucket에 저장하는 엔드투엔드 데이터 파이프라인이다.
이 파이프라인은 ETL/MLOps 구조를 축소형으로 완전하게 재현한 버전이며, 이후 MLflow → 모델 학습 자동화와 연결될 기반이 된다.
1️⃣ 전체 구조
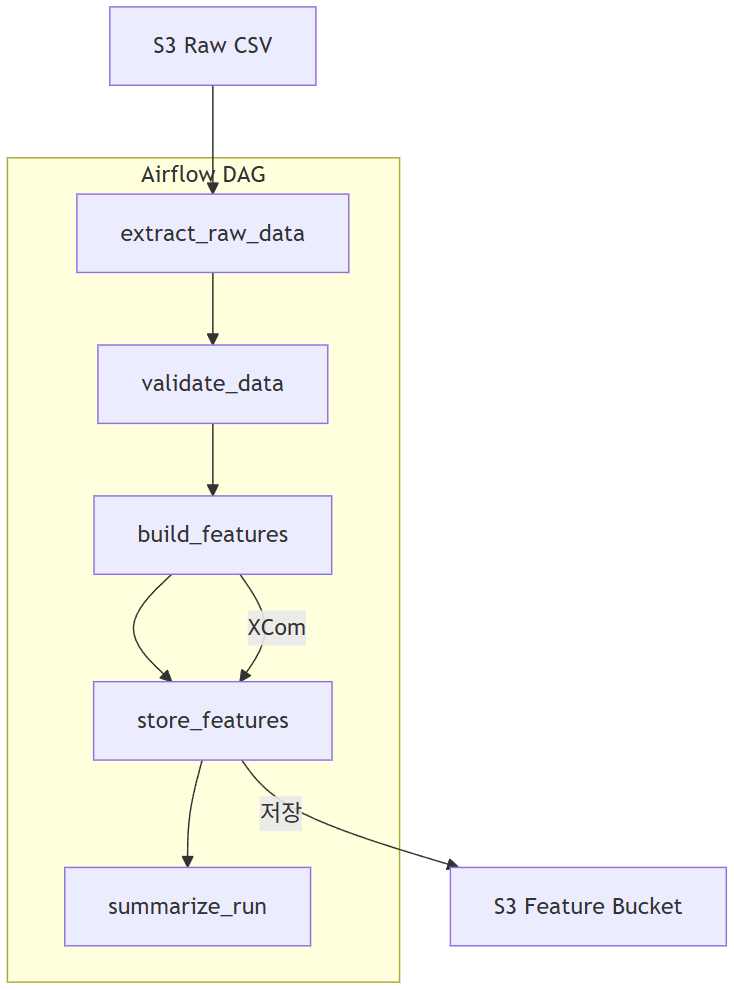
2️⃣ 구성 요소
| 구성 요소 | 설명 |
|---|---|
| S3 Raw Bucket | s3://datapipeline-raw-data-keonho |
| S3 Feature Bucket | s3://datapipeline-feature-data-keonho |
| Airflow | DAG 스케줄링, Task 관리 |
| Python 전처리 코드 | CSV 파싱, 검증, Feature 생성 |
| XCom | Task 간 데이터 전달 |
| Kubernetes | Airflow Worker 운영 |
3️⃣ Repo 및 디렉터리 구조
airflow-dags-dev/
├── dags/
│ ├── dag_data_pipeline_daily.py
│ └── ml_code/
│ └── data_pipeline.py
- DAG 스케줄 정의:
dag_data_pipeline_daily.py - ETL 로직:
ml_code/data_pipeline.py
4️⃣ E2E Pipeline Flow
전체 흐름
- extract_raw_data: S3 Raw CSV 헤더 확인 → CSV 내용 읽기 → XCom으로 Text 전달
- validate_data: CSV 구조 검증 (헤더, 최소 컬럼 수, 결측 체크)
- build_features: 숫자형 컬럼 자동 탐지 → 전처리 → row_sum Feature 생성 → Feature CSV를 XCom으로 전달
- store_features: 전달받은 Feature CSV → S3 Feature Bucket에 저장
- summarize_run: 처리 결과 로깅 (row 수, 저장 경로 등)
Pipeline = 추출 → 검증 → 가공 → 저장 → 요약으로 구성된 ETL 구조다.
5️⃣ Raw 데이터 구조
예시 파일:
s3://datapipeline-raw-data-keonho/user_events_20251119.csv
CSV 헤더:
event_time,user_id,session_id,event_type,device,country,is_premium,event_value,amount,session_length_sec
이 이벤트 기반 Raw 로그는 실무에서 자주 사용하는 형태이며 Feature 엔지니어링의 기본 단위다.
6️⃣ DAG 구성
DAG는 다음 5개 Task로 구성:
extract_raw_data → validate_data → build_features → store_features → summarize_run
DAG 예시:
task_extract_raw_data = PythonOperator(
task_id="extract_raw_data",
python_callable=extract_raw_data,
op_kwargs={"raw_path": raw_s3_path},
)
Airflow Worker → Python → AWS SDK (boto3) 순으로 호출된다.
7️⃣ Python 전처리 코드 핵심
모든 실전형 파이프라인이 공통적으로 가져야 하는 Extract → Validate → Transform → Load(E2E) 흐름을 충실히 구현했다.
✔ 1) extract_raw_data()
head_object로 파일 존재 여부 확인- CSV Raw 텍스트 로딩
- XCom push
✔ 2) validate_data()
- header 존재 체크
- row 길이 검증
- 유효하지 않은 라인은 drop
- 기본적인 Schema Validation 역할
✔ 3) build_features() (핵심)
자동 숫자형 컬럼 탐지:
numeric_candidates = {"user_id", "is_premium", "event_value", "amount", "session_length_sec"}
numeric_indices = [
idx for idx, col in enumerate(header) if col in numeric_candidates
]
- 헤더와 후보 목록을 비교하여 존재하는 컬럼만 자동 추출
- Raw 파일이 컬럼 추가/변경되어도 안정적으로 동작
Feature 생성 로직:
numeric_values.append(float(cell)) if 가능 else 0.0
row_sum = sum(numeric_values)
- 숫자로 파싱되지 않으면 0.0 처리
- 레코드 단위 Feature(row_sum) 생성
✔ 4) store_features()
XCom에서 feature_csv 문자열 수신 → S3 Feature Bucket 저장:
s3://datapipeline-feature-data-keonho/features_20251119.csv
✔ 5) summarize_run()
- 생성된 Feature row count
- 처리한 파일명
- 저장 경로
- Task 성공/실패 로그
8️⃣ Feature 결과 예시
생성된 row_sum feature 예시:
1302.0
36733.0
1185.0
1546.0
...
Raw → 숫자 컬럼 → 전처리 → Feature 정상적으로 추출된 pipeline의 대표적인 출력물이다.
9️⃣ 실전 Troubleshooting 정리
✔ S3 HeadObject 확인
action=head_object 로깅으로 Raw 파일 누락 여부 확인 가능.
✔ Worker Pod 로그
kubectl -n airflow-dev logs <pod>
파이프라인 실패 원인 대부분이 여기서 드러난다.
✔ NameResolutionError
Airflow UI에서 Worker Log 조회 시 종종 발생하는 정상 현상 (Worker Pod는 ephemeral이므로 문제 없음)
✔ CSV Parsing 실패
- “열 개수가 일정하지 않음”
- “빈 라인 포함”
→ validate_data()에서 기본적으로 방어됨.
설계 판단 (Why This Way?)
소규모 데이터에서는 XCom이 가장 단순한 Task 간 통신 수단이므로 S3 중간 저장의 추가 복잡도를 피했고, validate_data를 별도 Task로 분리하여 검증 실패 시 이후 파이프라인을 조기 차단합니다. 숫자형 컬럼 후보를 명시적으로 하드코딩하여 스키마 자동 추론의 예측 불가능한 타입 변환을 방지했습니다.
다음에 읽을 글
→ Observability 8단계: Data Pipeline 고도화 — Grafana + Loki 통합 모니터링