이 글에서 다루는 것
FastAPI ML 서빙 환경에서 장애를 즉시 감지하고 원인을 추적할 수 있는 대시보드 3종과 Alert Library 4종을 구축한 과정
선수지식
이 단계에서 해결하려는 문제
FastAPI는 모델을 서빙하는 입구이자, 장애가 나면 가장 먼저 흔들리는 지점이다. A/B, Canary, 핫스왑 구조 위에서 문제가 생기면 바로 감지되고 원인을 바로 찾을 수 있는 관측 체계가 필요하다. 이번 단계에서는 실제 운영 수준의 FastAPI Observability Dashboard와 Alert Library를 구축한다.
🎯 핵심 요약
- 목표: FastAPI 기반 ML Serving 환경에서 실제 운영 가능한 수준의 관측/알람 체계 구축
- 사용 기술: Prometheus, Grafana, Loki & Promtail, Alertmanager, Kubernetes + Ingress + ArgoCD
- 운영 포인트
- dev / prod 완전 분리된 Observability 스택
- 모든 대시보드/알람은 GitOps로 재현 가능
- FastAPI 서빙, 모델 핫스왑, A/B 로직과 자연스럽게 연결되는 구조
1️⃣ 전체 구조 개요
FastAPI는 단순 API 서버가 아니라 모델 A/B 테스트 → Canary 롤아웃 → 핫스왑 → 롤백까지 이어지는 ML 서빙 파이프라인의 핵심이다.
따라서 FastAPI 관측은 다음 3가지를 동시에 만족해야 한다:
- 서비스 레벨 지표 (RPS, 지연시간, Error Rate)
- 시스템 레벨 지표 (CPU, 메모리, Pod 상태, Node Health)
- 로그 기반 관측 (Error Path, Slow Path 분석)
이 3가지를 하나의 흐름으로 연결한 것이 이번에 구축한 대시보드 + Alert Library다.
🧩 아키텍처 흐름
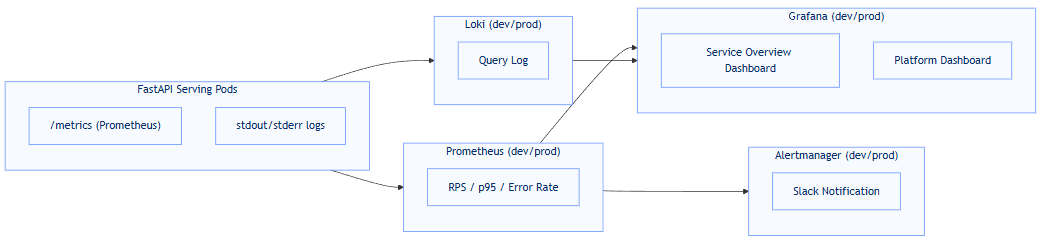
2️⃣ 대시보드 구성
이번 글에서는 운영 효용이 가장 높은 2개의 대시보드를 다룬다.
- Dashboard 1 – FastAPI Service Overview
- Dashboard 2 – Platform - Kubernetes & Nodes
3️⃣ Dashboard 1 – FastAPI Service Overview
FastAPI 운영에서 가장 중요한 지표만 담은 장애 감지용 대시보드다.
📌 포함된 주요 패널
- 요청량 (RPS: Requests Per Second)
- 지연시간 분포 (p95 latency)
- Error Rate (%)
- 상태 코드 분포 (2xx / 4xx / 5xx)
- CPU / 메모리 사용량
- Pod Count, Restart Count
- Loki 로그: Error / Warning / Slow Request
📌 설계 시 가장 중요하게 고려한 것
- 이슈 처음 감지에 필요한 지표만 추림
- 로그와 메트릭을 동시에 볼 수 있게 배치
- RPS와 p95는 항상 같은 축에 두어 트래픽 증가 → 지연 증가 패턴이 즉시 보이도록 구성
- 슬로우 쿼리/오류 로그는 instant query가 아니라 range query 기반으로 구성하여 Loki 특성을 반영
이 대시보드는 실제 장애가 날 때 제일 먼저 보는 화면을 목표로 한다.
4️⃣ Dashboard 2 – Platform - Kubernetes & Nodes
FastAPI만 보는 것으로는 부족하기 때문에 플랫폼 자체의 건강 상태를 살펴보는 대시보드도 함께 구성한다.
📌 주요 패널
- Node CPU, Memory, Disk 사용량
- Pod 상태 (Pending, CrashLoopBackOff)
- kubelet / API Server 기본 메트릭
- 스케줄러/컨트롤러 건강 (필요 시)
- Prometheus / Loki / NFS 관련 핵심 메트릭
📌 왜 필요한가?
FastAPI가 500을 뱉는 이유는 항상 FastAPI 코드 때문이 아니다.
- 노드 디스크가 꽉 찼거나
- 네트워크 패킷 드롭이 발생하거나
- 스케줄러가 잠시 지연되거나
- PVC I/O가 병목이거나
이런 플랫폼 레벨의 이슈가 전체 장애를 유발할 수 있기 때문에 서비스 관측 + 플랫폼 관측은 항상 세트로 가져가야 한다.
(+) FastAPI A/B & Model Deep Dive Dashboard
FastAPI Service Overview가 장애 감지용 레이더라면, 별도로 구축한 A/B & Model Deep Dive 대시보드는 /predict, /variant/{alias}/predict 같은 모델 서빙 엔드포인트만 집중적으로 분석하기 위한 화면이다.
http_requests_total,http_request_duration_seconds_bucket메트릭 기반- handler별 RPS / p50 / p95 / Error Rate / Slow handler 순위
- Loki 로그 패널과 함께 붙여서 지연이나 에러가 어떤 엔드포인트에서 발생했는지를 바로 확인
이 대시보드는 모델 버전 교체(핫스왑) 이후, A/B 트래픽 분포와 tail latency 변화를 빠르게 검증하는 데 사용한다.
5️⃣ Alert Library (PrometheusRule)
이번 6단계에서는 FastAPI 핵심 Alert 4종을 정리했다.
(실제 환경에서 수집 중인 http_requests_total, http_request_duration_seconds_bucket 메트릭 기준으로 작성)
✔ 1) FastAPIHighErrorRate
- alert: FastAPIHighErrorRate
expr: (
sum(rate(http_requests_total{status!~"2..", handler!=""}[2m]))
/
sum(rate(http_requests_total{handler!=""}[2m]))
) > 0.05
for: 1m
labels:
severity: critical
annotations:
summary: "FastAPI 에러율 증가"
description: "5xx 또는 비정상 응답 비율이 5%를 초과했습니다."
✔ 2) FastAPIP95LatencyHigh
- alert: FastAPIP95LatencyHigh
expr: histogram_quantile(
0.95,
sum by (le) (
rate(http_request_duration_seconds_bucket{handler!=""}[2m])
)
) > 0.1
for: 2m
labels:
severity: warning
annotations:
summary: "FastAPI p95 지연시간 증가"
description: "전체 핸들러 p95 latency > 100ms"
✔ 3) FastAPIInstanceDown
- alert: FastAPIInstanceDown
expr: up{job=~"fastapi-.*"} == 0
for: 30s
labels:
severity: critical
annotations:
summary: "FastAPI 인스턴스 다운"
description: "fastapi pod가 응답하지 않습니다."
실제 환경에서는 job 라벨을 fastapi-dev, fastapi-prod 등으로 분리해서 운용할 수 있다.
✔ 4) FastAPILogErrorSpike (Loki Alerts)
- alert: FastAPILogErrorSpike
expr: sum(rate({app=~"fastapi-.*"} |= "ERROR" [5m])) > 5
for: 2m
labels:
severity: warning
annotations:
summary: "FastAPI ERROR 로그 증가"
description: "에러 로그가 5분 동안 비정상적으로 증가했습니다."
6️⃣ Alertmanager → Slack Notification
Alertmanager 구성 구조를 그대로 사용하며, FastAPI 전용으로 분기하는 Slack 라우팅 규칙만 강조한다:
routes:
- match_re:
alertname: "FastAPI.*"
receiver: slack_fastapi
receivers:
- name: slack_fastapi
slack_configs:
- channel: "#fastapi-alerts"
FastAPI 관측 관련 알람은 모두 #fastapi-alerts로 분리되어 들어오도록 구성한다.
7️⃣ 실전 예시 – 장애 발생 시 흐름
다음과 같은 상황을 가정한다.
- 모델 핫스왑 직후
- 새로운 모델이 예외를 발생시키고
- FastAPI Error Rate가 12%로 상승
- p95 latency도 튀기 시작
📌 실제로는 이렇게 보인다
- FastAPIHighErrorRate → Slack Alert
- FastAPIP95LatencyHigh → Slack Alert
- Service Overview Dashboard의 Error Plot 급등
- Loki Error 로그 패턴 반복
- 필요 시 A/B 또는 모델 버전 롤백 실행
이 흐름 하나만으로도 자동화된 모델 운영 + 장애 복구라는 ML Platform 운영의 그림이 완성된다.
🧩 팁
- p95를 p99보다 우선적으로 쓰는 이유: 운영 중에는 극단치(p99)는 노이즈가 많아 관리 난이도가 높다.
- Error Rate는 1%부터도 장애 패턴이 나타나는 경우가 흔하다.
- Loki instant query는 지원 안 되므로 대시보드는 range query 기반으로 구성해야 안전하다.
설계 판단 (Why This Way?)
대시보드를 서비스/플랫폼/모델 3종으로 분리하여 장애 시 on-call 엔지니어가 핵심 지표에 즉시 접근하도록 했습니다. Alert 임계값은 보수적으로 시작하여 실 트래픽 기반으로 튜닝하고, Prometheus(무엇이 문제)와 Loki(왜 문제) Alert를 병행하여 원인 분석 시간을 단축합니다.
다음에 읽을 글
→ Observability 7단계: Data Pipeline 구축 — Airflow 기반 데이터 수집 파이프라인