이 글에서 다루는 것
kube-prometheus-stack을 dev/prod 네임스페이스로 완전 분리하고, ArgoCD GitOps로 재현 가능한 Observability 뼈대를 구축하는 과정을 다룹니다.
선수지식
- Airflow 7단계: DAG CI 구축 — Level 3 마지막 포스트
이 단계에서 해결하려는 문제
모니터링은 한 번 세팅해두고 끝나는 게 아니라, 클러스터를 갈아엎어도 같은 모습으로 다시 살아나야 하는 인프라다. kube-prometheus-stack을 dev/prod로 완전히 분리하고, 모든 구성을 YAML + GitOps로 고정해서 Observability 스택을 재현할 수 있는 뼈대를 먼저 만든다.
🎯 핵심 요약
목표
monitoring-dev / monitoring-prodObservability 스택을 YAML + GitOps만으로 그대로 재현할 수 있는 상태 만들기
구성 요소
kube-prometheus-stack 65.5.0(Prometheus + Alertmanager + Grafana)nfs-monitoringStorageClass (NFS 기반 동적 프로비저닝)nginx-ingress기반 HTTPS IngressArgoCD Application2개 (monitoring-dev,monitoring-prod)
보안/운영 포인트
- Grafana admin 계정은 Secret으로 분리
- Alertmanager / Slack / TLS / SealedSecret 세부 구성은 시리즈 단계별로 확장
1️⃣ 전체 구조 개요
- Kubernetes 위에
monitoring-dev네임스페이스monitoring-prod네임스페이스
- 두 네임스페이스마다
- kube-prometheus-stack 1개씩 배포
- Prometheus, Alertmanager, Grafana 각각 독립
- 모든 매니페스트는 Git 리포지토리에서 관리
apps/monitoring-dev.yamlapps/monitoring-prod.yaml- ArgoCD가 Auto Sync + SelfHeal 로 관리
🧩 아키텍처 흐름
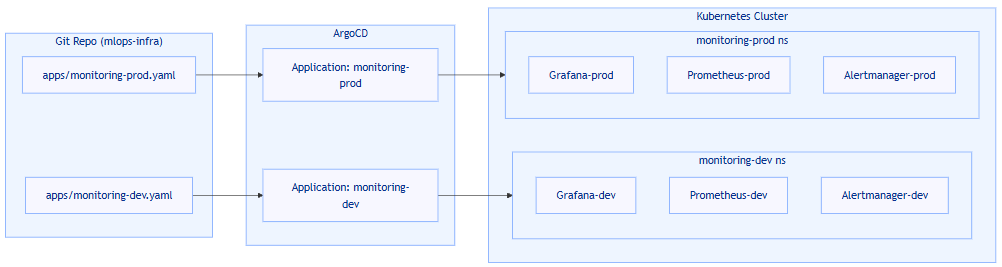
Slack, TLS, Loki, FastAPI Metrics 등은 이 구조 위에 레이어처럼 하나씩 올리는 방식으로 진행한다.
2️⃣ 사전 준비 체크리스트
인프라 전제
- Kubernetes 클러스터 (master + worker 구조)
-
kubectl+helm사용 가능 -
ArgoCD설치 및 동작 중 (argocd네임스페이스) -
nginx-ingress컨트롤러 설치 완료 - Git 리포지토리 구조에
apps/디렉터리 존재
NFS / Storage
- NFS 서버 (예:
192.168.18.141) -
/mnt/nfs_share/mlops/monitoring디렉터리 생성 -
nfs-monitoringStorageClass (동적 프로비저너) 생성
Prometheus는 1차 버전에서는 NFS 위에 올려두고, 나중에 local-path 기반 TSDB 최적화로 바꿔가는 흐름으로 이어간다.
3️⃣ NFS 및 StorageClass 구성
3-1. NFS 서버 설정
NFS 서버(예: 192.168.18.141)에서:
sudo mkdir -p /mnt/nfs_share/mlops/monitoring
sudo chmod -R 0777 /mnt/nfs_share/mlops/monitoring
/etc/exports:
/mnt/nfs_share/mlops/monitoring 192.168.18.0/24(rw,sync,no_subtree_check,no_root_squash)
적용 & 확인:
sudo exportfs -ra
showmount -e 192.168.18.141
# /mnt/nfs_share/mlops/monitoring 192.168.18.0/24
3-2. NFS 동적 프로비저너 설치
관리가 편해야 하니, nfs-subdir-external-provisioner로 동적 프로비저닝을 쓴다.
helm repo add nfs-subdir-external-provisioner https://kubernetes-sigs.github.io/nfs-subdir-external-provisioner/
helm repo update
kubectl create ns storage --dry-run=client -o yaml | kubectl apply -f -
helm upgrade --install nfs-monitoring \
nfs-subdir-external-provisioner/nfs-subdir-external-provisioner \
-n storage \
--set nfs.server=192.168.18.141 \
--set nfs.path=/mnt/nfs_share/mlops/monitoring \
--set storageClass.name=nfs-monitoring \
# ... (이하 생략)
확인:
kubectl get sc
# NAME PROVISIONER DEFAULT
# nfs-monitoring k8s-sigs.io/nfs-subdir-external-provisioner no
이후에 생성하는 PVC에서 storageClassName: nfs-monitoring만 지정하면 자동으로 PV + 하위 디렉터리가 생성된다.
4️⃣ Namespace & 기본 Secret 구성
4-1. Namespace 생성
kubectl create ns monitoring-dev
kubectl create ns monitoring-prod
이미 있다면 에러가 나와도 상관 없다.
4-2. Grafana Admin Secret
초기 로그인용 계정을 네임스페이스별로 분리한다.
# dev
kubectl -n monitoring-dev create secret generic grafana-admin-secret-dev \
--from-literal=admin-user=admin \
--from-literal=admin-password='<ADMIN_PASSWORD>'
# prod
kubectl -n monitoring-prod create secret generic grafana-admin-secret-prod \
--from-literal=admin-user=admin \
--from-literal=admin-password='<ADMIN_PASSWORD>'
실제 환경에서는 <ADMIN_PASSWORD> 대신 별도 패스워드 관리자에서 가져온 값을 사용하고, 이후에는 SealedSecret로 전환하는 것을 권장한다.
▶ SealedSecret 변환 예시(dev)
kubectl -n monitoring-dev create secret generic grafana-admin-secret-dev \
--from-literal=admin-user=admin \
--from-literal=admin-password='<실제_관리자_패스워드>' \
--dry-run=client -o yaml \
| kubeseal --controller-namespace=sealed-secrets \
--controller-name=sealed-secrets \
--format=yaml \
> sealed-secrets/grafana-admin-secret-dev.yaml
prod도 동일하다.
5️⃣ ArgoCD Application 정의 (kube-prometheus-stack)
Git 리포지토리의 apps/ 아래에 monitoring-dev와 monitoring-prod Application을 정의한다.
5-1. monitoring-dev Application
apps/monitoring-dev.yaml:
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: monitoring-dev
namespace: argocd
annotations:
argocd.argoproj.io/sync-options: >
SkipDryRunOnMissingResource=true,PruneLast=true,ServerSideApply=true
spec:
project: dev
destination:
server: https://kubernetes.default.svc
namespace: monitoring-dev
source:
repoURL: https://prometheus-community.github.io/helm-charts
chart: kube-prometheus-stack
targetRevision: 65.5.0
helm:
skipCrds: true
values: |
grafana:
admin:
existingSecret: grafana-admin-secret-dev
userKey: admin-user
passwordKey: admin-password
ingress:
enabled: true
ingressClassName: nginx
hosts:
- grafana-dev.local
persistence:
enabled: true
storageClassName: nfs-monitoring
size: 10Gi
alertmanager:
alertmanagerSpec:
configSecret: alertmanager-config-dev
# ... (이하 storage/ingress 설정 생략)
prometheus:
prometheusSpec:
serviceMonitorSelector:
matchLabels:
release: monitoring-dev
podMonitorSelector:
matchLabels:
release: monitoring-dev
ruleSelector:
matchLabels:
release: monitoring-dev
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: nfs-monitoring
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 50Gi
retention: 15d
retentionSize: 30GiB
kubeEtcd:
enabled: false
kubeControllerManager:
enabled: false
kubeScheduler:
enabled: false
kubeProxy:
enabled: false
coreDns:
enabled: false
초기 버전이라 Prometheus도 NFS를 쓰고 있다. 나중에 “Prometheus만 local-path로 옮기는 과정"을 별도 글로 다루면서 실무형 구조로 업그레이드한다.
5-2. monitoring-prod Application
apps/monitoring-prod.yaml 도 동일 구조로, monitoring-prod / grafana-prod.local / retention: 30d 등 환경별 값만 교체한다.
6️⃣ ArgoCD Sync & 첫 기동 검증
6-1. Application 적용
kubectl -n argocd apply -f apps/monitoring-dev.yaml
kubectl -n argocd apply -f apps/monitoring-prod.yaml
argocd app sync monitoring-dev
argocd app sync monitoring-prod
6-2. 리소스 상태 확인
kubectl -n monitoring-dev get pods,svc,pvc
kubectl -n monitoring-prod get pods,svc,pvc
확인 포인트:
-
prometheus-...,alertmanager-...,grafana-...Pod 모두 Running - PVC가 Bound 상태
6-3. Ingress & /etc/hosts
로컬 PC의 /etc/hosts 에 다음을 추가한다.
192.168.18.240 grafana-dev.local alert-dev.local prometheus-dev.local
192.168.18.240 grafana-prod.local alert-prod.local prometheus-prod.local
이후 브라우저에서 https://grafana-dev.local / https://grafana-prod.local 로 접근한다.
TLS 인증서는 이후 단계에서 SealedSecret + self-signed 발급 과정을 정리한다. 여기서는 “Ingress -> Service -> Pod” 경로가 정상인지에만 집중하면 된다.
7️⃣ Smoke Check
Slack 연동까지는 다음 단계에서 다루고, 여기서는 “PrometheusRule -> Prometheus -> Alertmanager” 기본 연결만 테스트한다.
7-1. dev용 Smoke Rule
cat <<'EOF' | kubectl -n monitoring-dev apply -f -
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: monitoring-smoke
labels:
release: monitoring-dev
spec:
groups:
- name: smoke.rules
rules:
- alert: Monitoring_Smoke_Dev
expr: vector(1)
for: 1m
labels:
severity: warning
namespace: monitoring-dev
annotations:
summary: "Monitoring dev smoke alert"
EOF
7-2. 상태 확인
1분 후:
curl -sk https://prometheus-dev.local/api/v1/alerts \
| jq '.data.alerts[] | select(.labels.alertname=="Monitoring_Smoke_Dev") | {state:.state, labels:.labels}'
state: "firing"이 나오면, PrometheusRule -> Prometheus 평가까지는 정상이다.- Alertmanager/Slack 라우팅은 다음 단계에서 이어서 구성한다.
테스트가 끝나면:
kubectl -n monitoring-dev delete prometheusrule monitoring-smoke
🧩 팁
- kubeEtcd / kubeScheduler 비활성화: 자체 관리하는 컨트롤 플레인에서는 etcd/스케줄러까지 모니터링하지 않아도 충분한 경우가 많다. 처음에는 꺼두고, 필요할 때만 켜는 게 노이즈 관리에 좋다.
- 라벨(
release=monitoring-{env})은 표준처럼 사용: 나중에 ServiceMonitor/PodMonitor/PrometheusRule을 추가할 때 이 라벨만 맞춰주면 dev/prod Prometheus에 자연스럽게 붙는다.
설계 판단 (Why This Way?)
dev/prod Prometheus를 네임스페이스로 분리하여 한쪽 장애가 다른 환경에 전파되지 않도록 하고, Observability 스택은 항상 가동 상태여야 하므로 ArgoCD SelfHeal로 drift를 자동 복구합니다. 스토리지는 NFS로 시작하되 TSDB I/O 병목이 실측된 후 local-path로 전환하는 근거 기반 전략을 택했습니다.
다음에 읽을 글
→ Observability 2단계: Alertmanager Slack & 트러블슈팅 — 알림 라우팅과 장애 대응