이 글에서 다루는 것
Triton READY 상태, Model Repository, FastAPI health/models/reload API, Metrics endpoint를 실제 실행 결과(Proof)로 검증
선수지식
Serving Runtime Proof
- 실제로 READY / Reload / Metrics까지 살아 있는가
들어가며
지금까지 이 시리즈에서는 다음을 설명했습니다.
- ML 플랫폼 구조
- GitOps 환경 설계
- Optional 레이어 분리
- E2E 파이프라인
- Drift Gate / Promotion 전략
- MLflow + Triton + FastAPI 서빙 구조
하지만 여기서 중요한 질문이 하나 남습니다.
이 시스템이 실제로 동작하는가?
많은 아키텍처 글이
다이어그램과 코드 설명으로 끝납니다.
하지만 실제 운영 환경에서는 다음이 더 중요합니다.
서빙 시스템이 실제로 살아 있는가
모델이 실제로 로드되었는가
API가 실제로 동작하는가
metrics가 실제로 수집되는가
그래서 이 프로젝트에서는
Serving Runtime 상태를 Proof 파일로 기록했습니다.
이 글에서는 다음 항목을 확인합니다.
Triton READY 상태
Model Repository 상태
FastAPI health
FastAPI models
Reload API
Metrics 노출
Serving Runtime Proof 구조
Serving Runtime 관련 증거는 다음 경로에 저장됩니다.
docs/proof/latest/
├─ e2e_success
└─ load-test
이 폴더에는 다음 파일들이 포함됩니다.
triton_dev_ready_and_repo_index.txt
triton_prod_ready_and_repo_index.txt
fastapi_dev_health_models_metrics.txt
fastapi_prod_health_models_metrics.txt
reload_dev_variant_A.json
이 파일들은 단순 로그가 아니라
서빙 시스템이 정상 동작했음을 보여주는 실행 결과입니다.
또한 GitOps 기반 환경에서는
Serving Runtime이 실제로 배포되어 있어야 합니다.
ArgoCD에서 FastAPI와 Triton이 정상 배포된 상태를 확인할 수 있습니다.
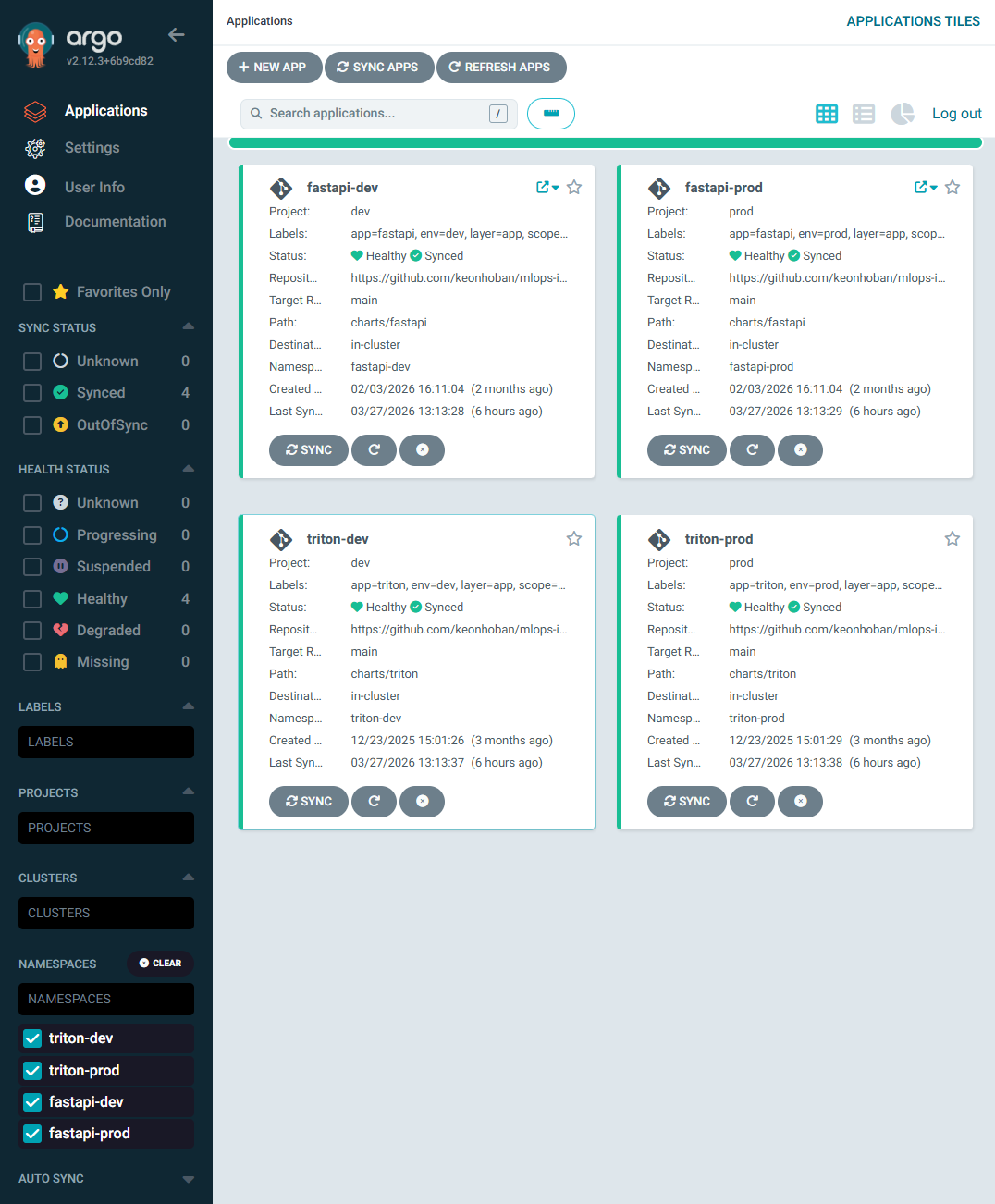
📸 proof-serving-00-argocd-applications.png
여기서 다음 애플리케이션이 모두 Healthy / Synced 상태입니다.
fastapi-dev
fastapi-prod
triton-dev
triton-prod
즉 GitOps 기반 배포 상태에서
Serving Runtime이 정상적으로 운영되고 있습니다.
Triton READY 상태 확인
먼저 Triton 서버가 정상적으로 실행되고 있는지 확인합니다.
Serving Runtime 확인을 위해
Kubernetes Service에 port-forward로 접근합니다.
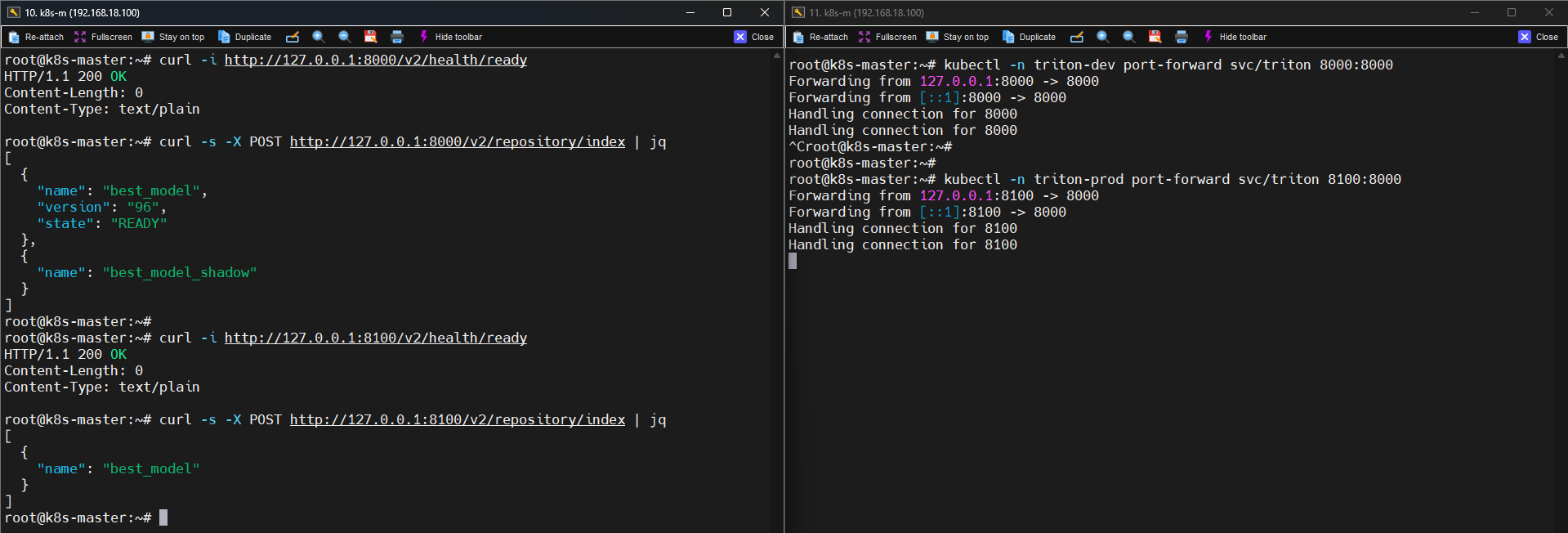
📸 proof-serving-01-triton-port-forward.png
예시:
kubectl -n triton-dev port-forward svc/triton 8000:8000
kubectl -n triton-prod port-forward svc/triton 8100:8000
이후 Triton readiness API를 호출합니다.
GET /v2/health/ready
결과:
HTTP/1.1 200 OK
이는 다음 의미를 가집니다.
Server Ready
Model Repository Loaded
Inference 가능
Triton Model Repository 상태
서버 상태만 확인하는 것으로는 충분하지 않습니다.
실제로 모델이 로드되어 있는지도 확인해야 합니다.
이를 위해 다음 API를 사용합니다.
POST /v2/repository/index
실제 결과 예시는 다음과 같습니다.
[
{"name":"best_model"},
{"name":"best_model_shadow"}
]
이 결과는 다음 의미를 가집니다.
best_model — 운영 서빙 모델
best_model_shadow — shadow 서빙 모델
즉 Triton Model Repository에서
두 모델이 모두 로드되어 서빙 가능 상태입니다.
참고: dev 환경은 단일 Triton 인스턴스에
best_model과best_model_shadow두 모델명을 배포합니다. 반면 prod 환경은 별도 Triton 인스턴스(triton-prod/triton-dev)를 운영하며, 두 인스턴스 모두 동일한 모델명(best_model)을 사용합니다. FastAPI의traffic_mode(mirror/split)로 트래픽을 제어합니다.
Production Triton 상태
운영 환경 Triton도 동일하게 확인합니다.
GET /v2/health/ready
POST /v2/repository/index
예시 결과:
[
{"name":"best_model"}
]
prod 환경은 best_model 단일 모델만 서빙합니다.
shadow 트래픽은 별도 Triton 인스턴스(triton-dev)가 담당하며,
FastAPI가 traffic_mode 설정에 따라 라우팅합니다.
즉 dev/prod 두 환경 모두 Triton serving runtime이 정상 동작합니다.
FastAPI Health 상태
다음으로 FastAPI gateway 상태를 확인합니다.
health endpoint:
GET /health
결과 예시:
{
"status":"ok"
}
이 결과는 다음을 의미합니다.
FastAPI server 정상
Serving gateway 정상
API 접근 가능
FastAPI Models API
FastAPI에는 현재 서빙 상태를 확인하는 API가 존재합니다.
GET /models
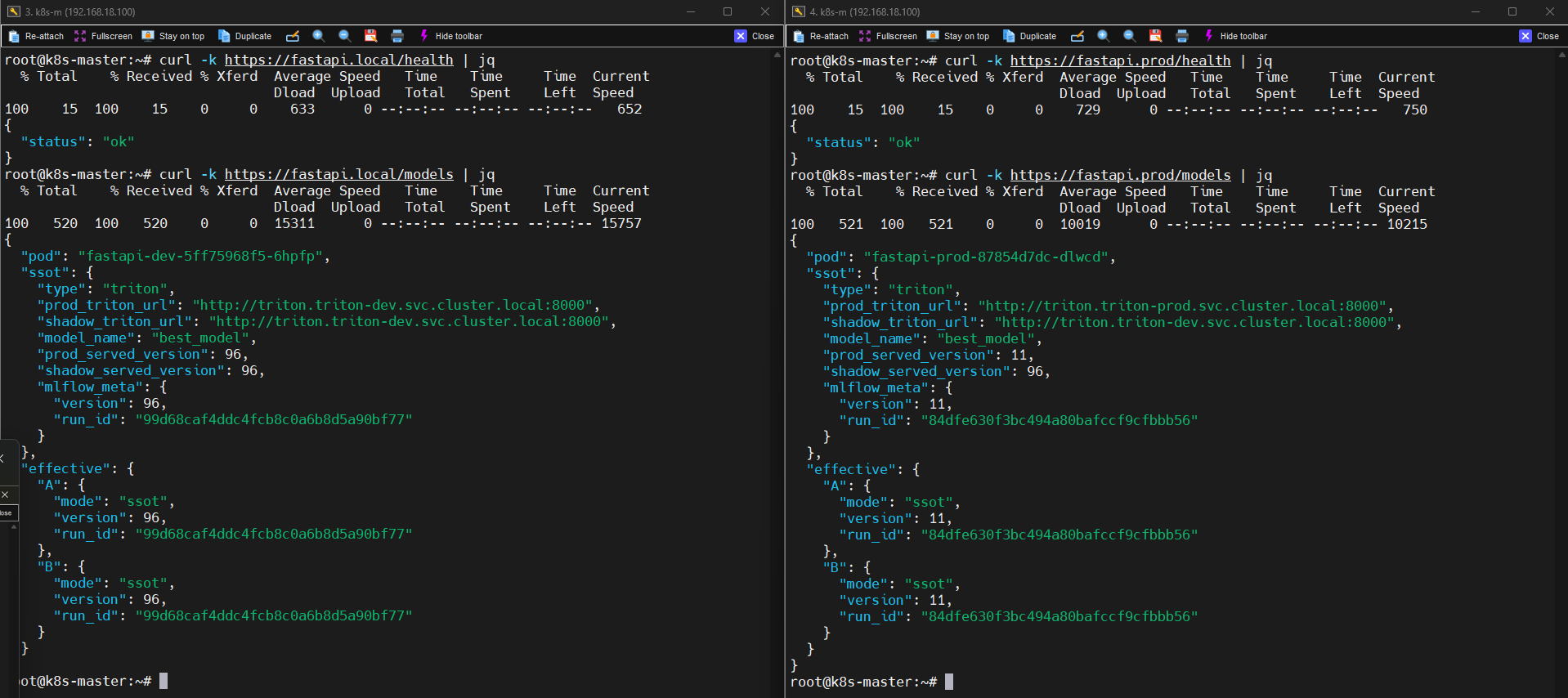
📸 proof-serving-02-fastapi-models.png
실제 응답 예시는 다음과 같습니다.
{
"pod":"fastapi-dev-xxxx",
"ssot":{
"type":"triton",
"prod_triton_url":"http://triton.triton-dev.svc.cluster.local:8000",
"shadow_triton_url":"http://triton.triton-dev.svc.cluster.local:8000",
"model_name":"best_model",
"prod_served_version":96,
"shadow_served_version":null,
"mlflow_meta":{
"version":96,
"run_id":"4b6de45..."
}
},
"effective":{
"A":{ "mode":"ssot","version":96,"run_id":"4b6de45..." },
"B":{ "mode":"ssot","version":96,"run_id":"4b6de45..." }
}
}
이 API는 다음 정보를 제공합니다.
현재 serving 모델 (prod/shadow 분리)
모델 version
MLflow run_id
Triton endpoint (prod/shadow)
즉 현재 운영 환경에서 어떤 모델이 서빙되고 있는지를
API를 통해 실시간으로 확인할 수 있습니다.
Reload API 동작 확인
모델 전환이 실제로 동작하는지도 확인합니다.
Reload API:
POST /variant/{alias}/reload
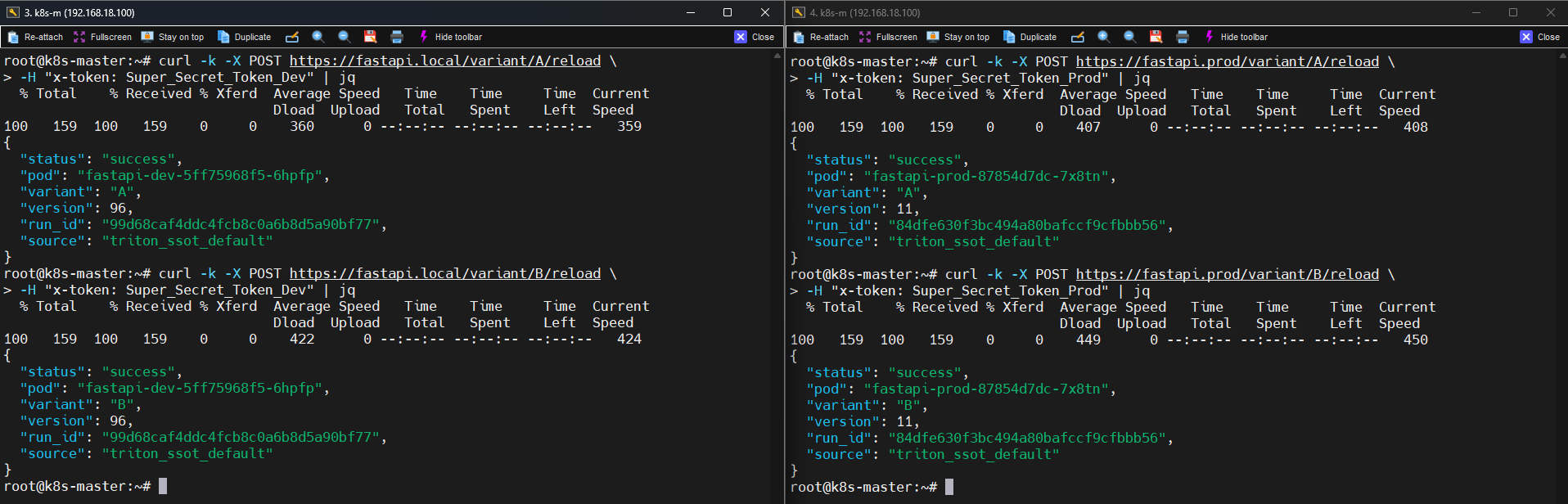
📸 proof-serving-03-fastapi-reload.png
실제 응답 예시는 다음과 같습니다.
{
"status":"success",
"pod":"fastapi-dev-xxxx",
"variant":"A",
"version":96,
"run_id":"4b6de45...",
"source":"triton_ssot_default"
}
이 결과는 다음을 의미합니다.
FastAPI reload 성공
alias 업데이트 완료
Triton model version 확인
source: SSOT 검증 방식 표시
즉 서빙 모델 전환이 정상적으로 수행되었습니다.
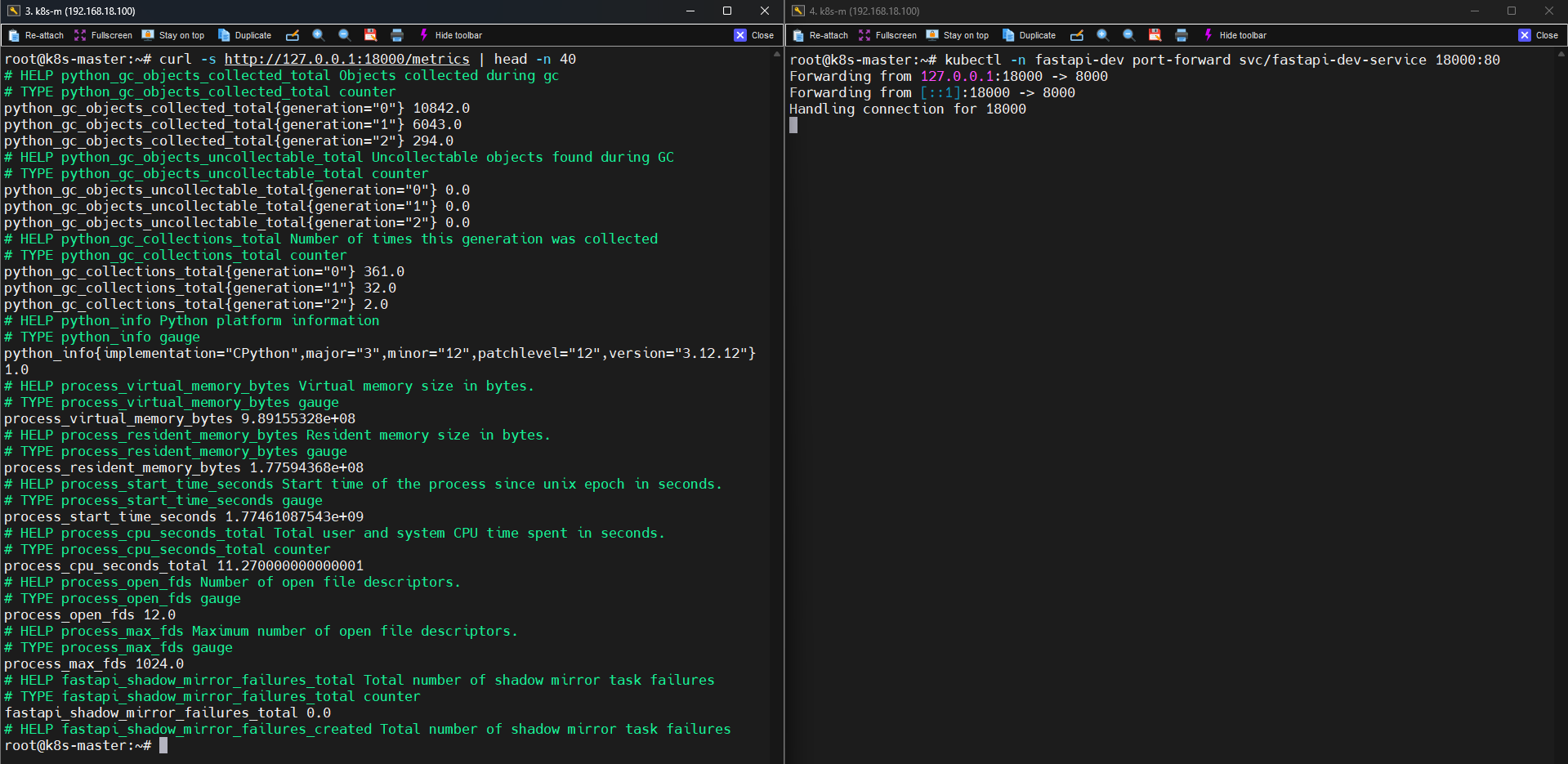
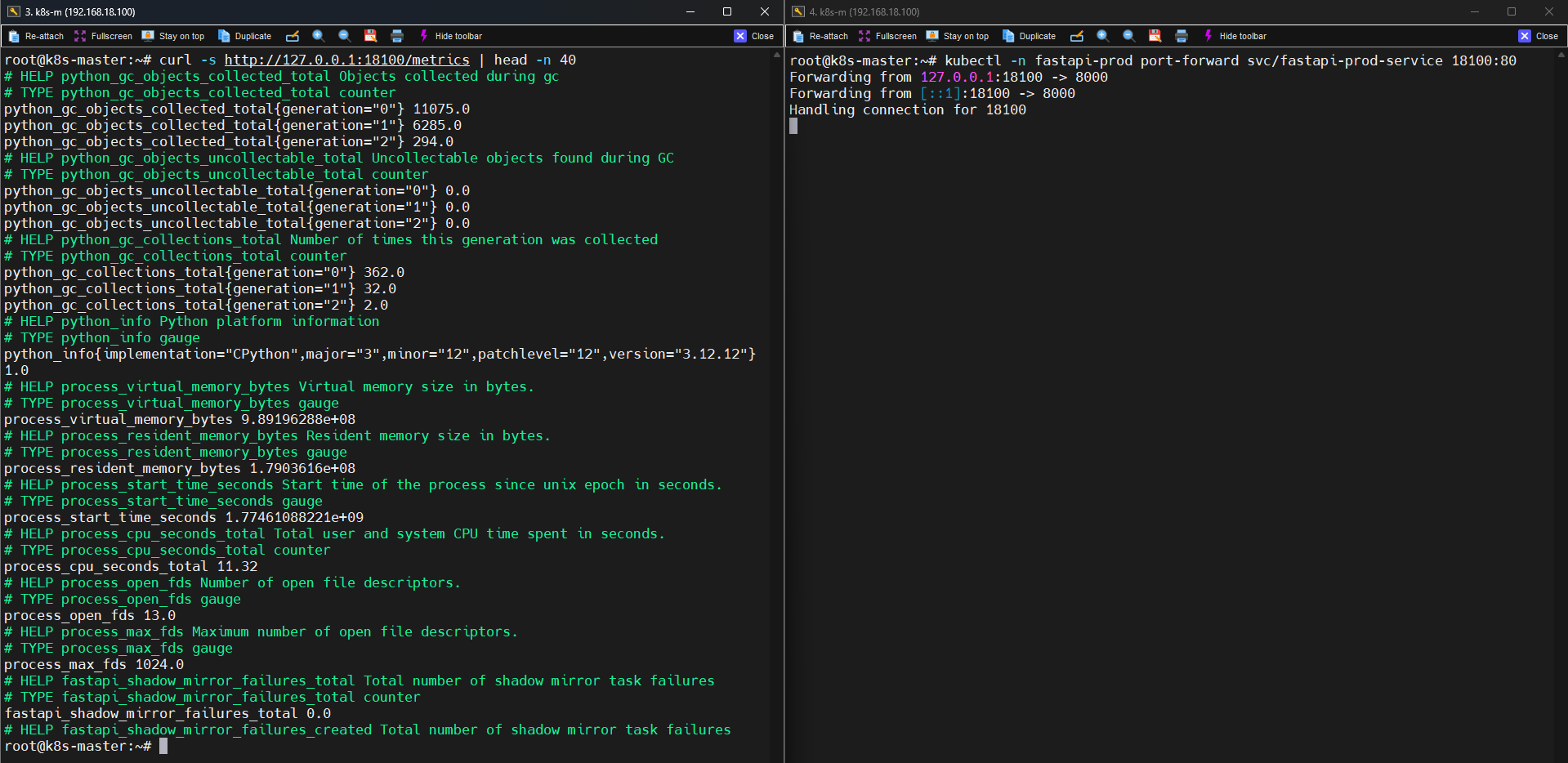
Metrics Endpoint
FastAPI는 Prometheus metrics exporter 역할도 합니다.
metrics endpoint:
GET /metrics
dev 환경 metrics:
📸 proof-serving-04-fastapi-metrics-portforward-dev.png
prod 환경 metrics:
📸 proof-serving-04-fastapi-metrics-portforward-prod.png
예시 metrics:
python_gc_objects_collected_total
process_cpu_seconds_total
http_requests_total
특히 다음 metric이 중요합니다.
http_requests_total{handler="/health"}
http_requests_total{handler="/metrics"}
http_requests_total{handler="/variant/{alias}/reload"}
즉
API 요청 수
서비스 상태
control API 호출
을 Prometheus에서 수집할 수 있습니다.
FastAPI / Triton 역할 분리
이 Proof를 통해 다음 구조가 실제로 동작함을 확인할 수 있습니다.
MLflow
↓
Model Registry
↓
Triton
↓
Serving Runtime
↓
FastAPI
↓
Serving Control Layer
각 시스템의 역할은 다음과 같습니다.
| 시스템 | 역할 |
|---|---|
| MLflow | 모델 기록 |
| Triton | 모델 서빙 |
| FastAPI | 서빙 제어 |
| Prometheus | metrics 수집 |
왜 Proof가 중요한가
많은 ML 플랫폼 글은 다음으로 끝납니다.
architecture diagram
code snippet
하지만 실제 플랫폼에서는 다음이 더 중요합니다.
실제로 서버가 살아 있는가
모델이 실제로 로드되었는가
API가 실제로 동작하는가
metrics가 실제로 수집되는가
그래서 이 프로젝트에서는
docs/proof/
디렉토리를 통해
실행 결과 자체를 기록하도록 설계했습니다.
핵심 메시지
이 글의 핵심 메시지는 다음입니다.
설계 ≠ 실행
아키텍처가 존재하는 것과
시스템이 실제로 동작하는 것은 다릅니다.
그래서 이 프로젝트에서는 다음을 확인했습니다.
Triton READY
Model Repository Loaded
FastAPI Health OK
Reload API Success
Metrics Exported
k6 부하 테스트: 136 RPS, p95 553ms, 에러율 0% (100 VU, 3노드 클러스터)
즉 이 플랫폼은
문서상 구조가 아니라 실제로 동작하는 시스템입니다.
다음 글
지금까지는 Serving Runtime을 확인했습니다.
하지만 ML 플랫폼에서 더 중요한 것은
운영 관측과 롤백 전략입니다.
다음 글에서는 다음 내용을 다룹니다.
Prometheus Observability
Alertmanager
Auto Rollback 정책
Manual Rollback DAG
관련 Proof:
docs/proof/latest/observability/*
dags/mlops_lib/observability/auto_rollback.py
dags/rollback_manual.py
이를 통해
배포 이후 시스템을 어떻게 감시하고 복구하는지
살펴보겠습니다.
설계 판단 (Why This Way?)
설계 문서만으로는 실제 동작을 증명할 수 없으므로 Serving Runtime 상태를 Proof 파일로 기록하고, dev/prod 양 환경을 동시에 검증하여 환경 일관성을 확인했습니다. k6 부하 테스트로 136 RPS, p95 553ms, 에러율 0%를 측정하여 단일 요청 성공을 넘어 실제 트래픽 환경에서의 안정성을 확인했습니다.
다음에 읽을 글
→ GitOps 기반 E2E ML Platform - 운영 제어 구조 — Observability / Auto Rollback / Manual Rollback