이 글에서 다루는 것
Kubernetes 기반 MLOps 인프라의 전체 구조를 설계하고, NFS/PostgreSQL/S3 기반 환경을 구축합니다.
선수지식
- Airflow 5단계: PythonOperator + MLflow Tracking 연동 — Level 1 완료 후 시작 권장
이 단계에서 해결하려는 문제
ML 모델을 실험하고 추적하려면 단순 Jupyter Notebook으로는 부족합니다. 학습 이력 추적(MLflow), 파이프라인 자동화(Airflow), 모델 서빙(FastAPI)을 하나의 플랫폼에서 운영하려면 Kubernetes 기반 인프라가 필요합니다. 이 단계에서는 그 기반이 되는 NFS, PostgreSQL, S3, Kubernetes 클러스터 환경을 설계하고 구축합니다.
아키텍처 구성도
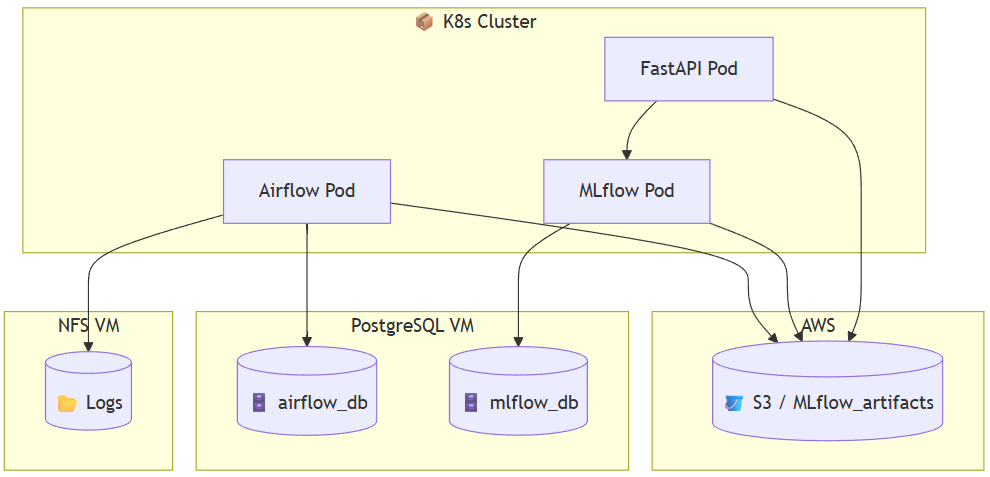
인프라 설계 개요
| 구성 요소 | 설명 |
|---|---|
| Kubernetes 클러스터 | 로컬 환경 (VMware) 기반. Helm & Ingress 활용 |
| MLflow 서버 | 외부 PostgreSQL + S3 연동. 모델 등록, 추적, 아티팩트 관리 |
| Airflow 서버 | DAG GitSync + S3 연동 + PostgreSQL 외부 DB 사용 |
| FastAPI 서버 | MLflow 모델 호출용 예측 API. Ingress로 외부 노출 |
| NFS 서버 | Airflow 로그 저장소로 사용. PVC로 연결됨 |
| AWS S3 | MLflow 아티팩트 저장소로 활용 |
| PostgreSQL | MLflow & Airflow의 metadata 저장소. 외부 VM에서 호스팅됨 |
각 구성 요소를 선택한 이유:
- Kubernetes: ML 모델 학습 및 서빙이 컨테이너 기반으로 이뤄지고 있으며, 자원 할당·스케일링·리소스 격리를 위한 플랫폼으로 사실상 표준
- NFS: MLflow 로그, 메타데이터 등 파일 기반 공유 스토리지가 필요하고, 로컬 볼륨은 Pod 재시작 시 휘발되므로 여러 Pod 간 공유가 가능한 스토리지가 필수 (실무에서는 AWS EFS, GCP Filestore 등 사용)
- PostgreSQL: MLflow/Airflow 메타데이터 저장소로 필요하며, SQLite는 실험용이고 운영 환경에서는 PostgreSQL이 필수. 외부에 위치시켜 트래픽 분리
- S3: 모델 artifact를 원격 오브젝트 스토리지에 두어 서빙/버전 관리/릴리즈 자동화가 가능해짐
📂 NFS 서버 구성
설치 & 공유 디렉토리 생성 (Ubuntu 기준)
sudo apt update
sudo apt install -y nfs-kernel-server
sudo mkdir -p /mnt/nfs_share/mlops/airflow/logs
sudo chown -R 50000:root /mnt/nfs_share/mlops/airflow # 사용할 유저 UID, GID 확인 필요
sudo chmod -R 775 /mnt/nfs_share/mlops/airflow
/etc/exports 설정
# 마운트 수가 적은 경우 (프로덕션 환경 적용시 root_squash 권장)
/mnt/nfs_share/mlops/airflow/logs 192.168.18.0/24(rw,sync,no_subtree_check,root_squash)
# 마운트 수가 많은 경우 (필요시)
/mnt/nfs_share/mlops 192.168.18.0/24(rw,sync,no_subtree_check,root_squash)
# 적용
sudo exportfs -rav
sudo systemctl restart nfs-kernel-server
PV & PVC 설정
# airflow-logs-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: airflow-logs-pv
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteMany
nfs:
server: 192.168.18.141
path: /mnt/nfs_share/mlops/airflow/logs
persistentVolumeReclaimPolicy: Retain
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: airflow-logs-pvc
namespace: airflow
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 5Gi
kubectl apply -f airflow-logs-pv.yaml
🗄 PostgreSQL 외부 DB 구성
설치 및 사용자/DB 생성
sudo apt install postgresql -y
sudo -u postgres psql
-- 데이터베이스 생성
CREATE DATABASE airflow_db;
CREATE DATABASE mlflow_db;
-- DB별 사용자 생성
CREATE USER airflow_user WITH PASSWORD '<YOUR_PASSWORD>'; -- 실제 환경: SealedSecrets 사용
CREATE USER mlflow_user WITH PASSWORD '<YOUR_PASSWORD>'; -- 실제 환경: SealedSecrets 사용
-- DB별 권한 부여
GRANT ALL PRIVILEGES ON DATABASE airflow_db TO airflow_user;
GRANT ALL PRIVILEGES ON DATABASE mlflow_db TO mlflow_user;
외부 접속 허용
/etc/postgresql/14/main/postgresql.conf
listen_addresses = '*'
/etc/postgresql/14/main/pg_hba.conf
host airflow_db airflow_user 192.168.18.0/24 scram-sha-256
host mlflow_db mlflow_user 192.168.18.0/24 scram-sha-256
sudo systemctl restart postgresql
🪣 S3 버킷 준비 (MLflow 아티팩트 저장소)
AWS S3 버킷 생성
- 버킷 이름:
mlflow-artifacts-keonho - 리전:
ap-northeast-2 - 퍼블릭 차단 유지, 기본 암호화 사용
IAM 사용자 생성 및 권한 부여
- 이름:
mlflow-airflow-user - 권한:
AmazonS3FullAccess(실습용) AWS_ACCESS_KEY_ID/AWS_SECRET_ACCESS_KEY저장
설계 판단 (Why This Way?)
로컬 환경에서는 NFS와 MinIO로 비용 없이 ReadWriteMany와 오브젝트 스토리지를 구현하되, PV/PVC 추상화로 프로덕션 전환 시 코드 변경 없이 EFS/S3로 교체할 수 있도록 설계했습니다. PostgreSQL은 클러스터 외부에 배치하여 Pod 재시작에 따른 데이터 유실을 방지하고 독립적 백업/모니터링을 가능하게 했습니다.
다음에 읽을 글
→ MLOps 플랫폼 구축 2단계: S3 & PostgreSQL 연동을 위한 구성 및 Secret 관리 전략 — Kubernetes Secret으로 인증 정보를 안전하게 주입하는 전략